Troubleshooting and Tuning Azure Cosmos DB Requests
In this lab, you will use the .NET SDK to tune an Azure Cosmos DB request to optimize performance of your application.
Setup
Before you start this lab, you will need to create an Azure Cosmos DB database and collection that you will use throughout the lab. You will also use Azure Data Factory to import existing data into your collection.
Create Azure Cosmos DB Database and Collection
You will now create a database and collection within your Azure Cosmos DB account.
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmosgroup-lab Resource Group.
-
In the cosmosgroup-lab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Overview link on the left side of the blade.
-
At the top of the Azure Cosmos DB blade, click the Add Collection button.
-
In the Add Collection popup, perform the following actions:
-
In the Database id field, select the Create new option and enter the value FinancialDatabase.
-
Ensure the Provision database throughput option is not selected.
-
In the Collection id field, enter the value TransactionCollection.
-
In the Partition key field, enter the value
/costCenter. -
In the Throughput field, enter the value
10000. -
Click the OK button.
-
-
Wait for the creation of the new database and collection to finish before moving on with this lab.
Retrieve Account Credentials
The Data Migration Tool and .NET SDKs both require credentials to connect to your Azure Cosmos DB account. You will collect and store these credentials for use throughout the lab.
-
On the left side of the Azure Cosmos DB blade, locate the Settings section and click the Keys link.
-
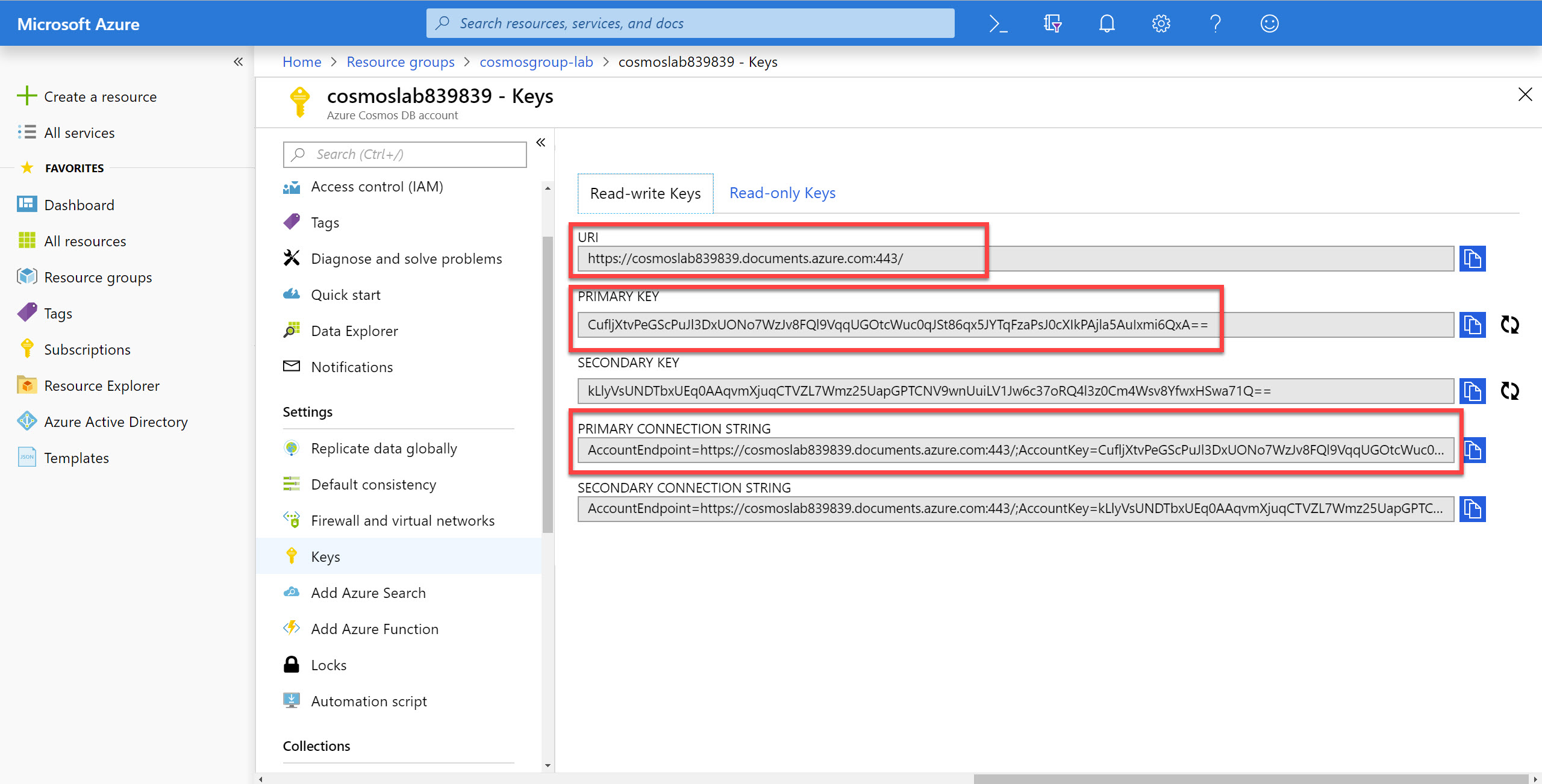
In the Keys pane, record the values in the CONNECTION STRING, URI and PRIMARY KEY fields. You will use these values later in this lab.
Import Lab Data Into Collection
You will use Azure Data Factory (ADF) to import the JSON array stored in the students.json file from Azure Blob Storage.
-
On the left side of the portal, click the Resource groups link.
To learn more about copying data to Cosmos DB with ADF, please read ADF’s documentation.
-
In the Resource groups blade, locate and select the cosmosgroup-lab Resource Group.
-
Click add to add a new resource
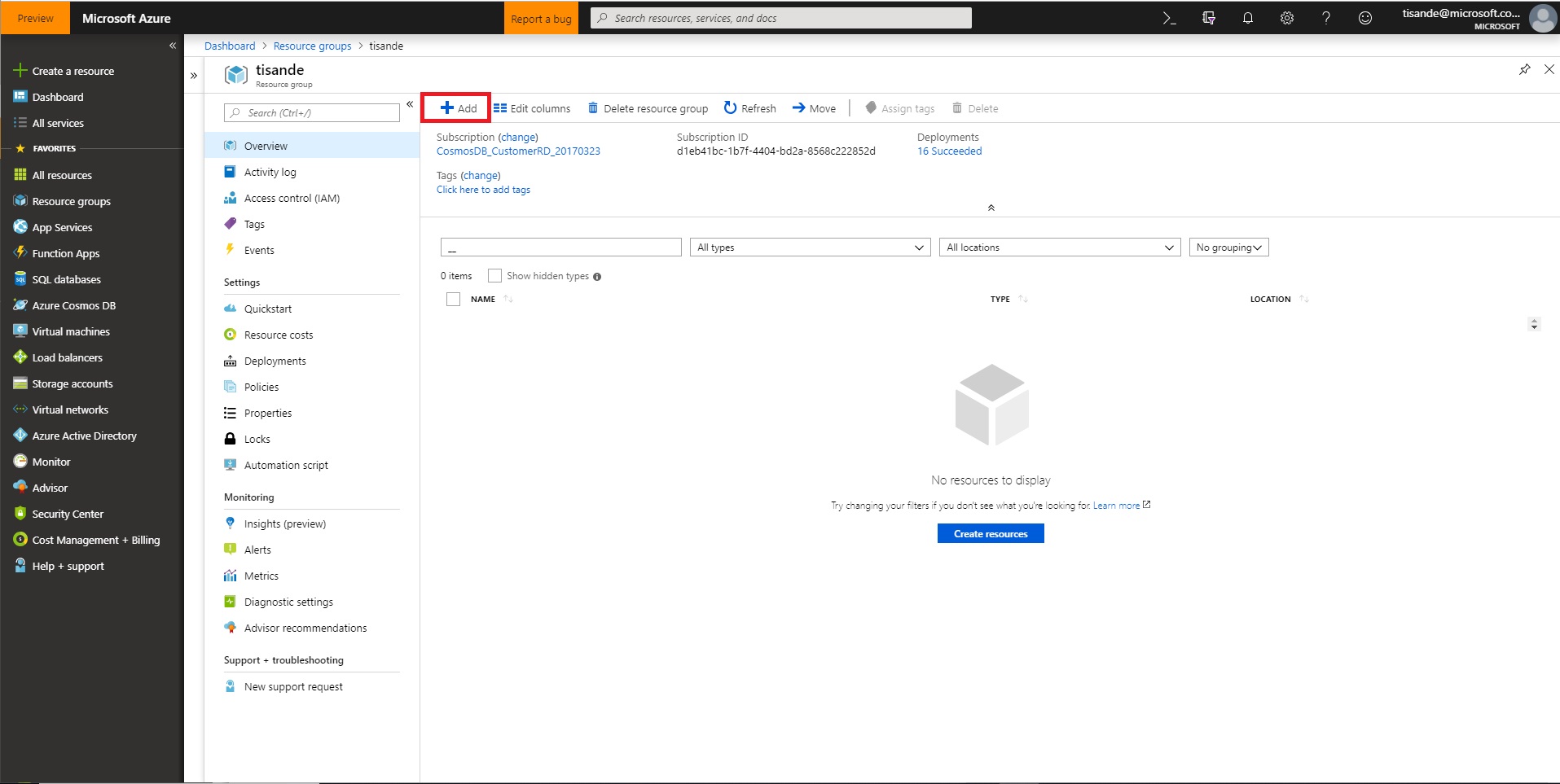
- Search for Data Factory and select it
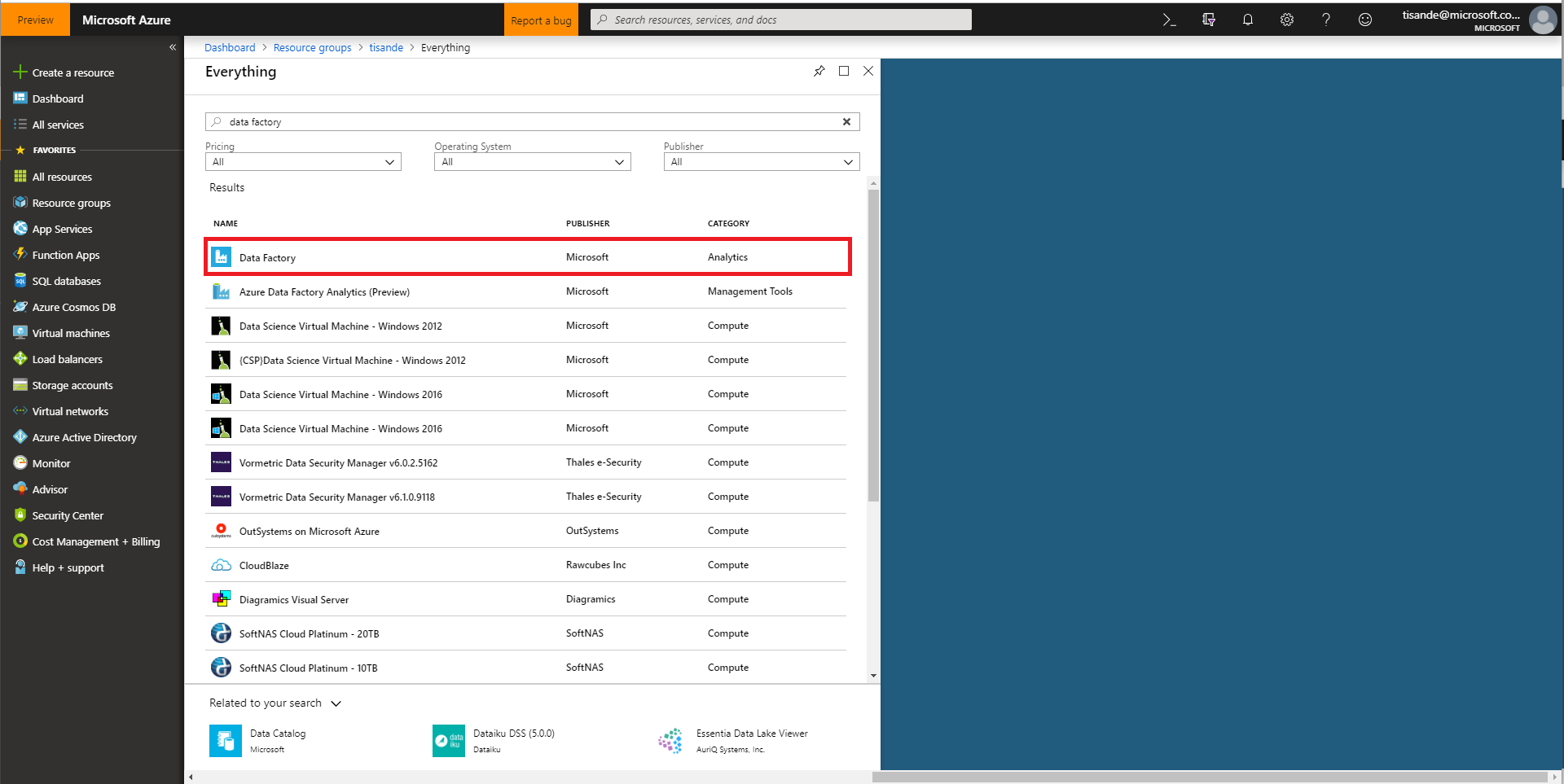
- Create a new Data Factory. You should name this data factory importtransactions and select the relevant Azure subscription. You should ensure your existing cosmosdblab-group resource group is selected as well as a Version V2. Select East US as the region. Click create.
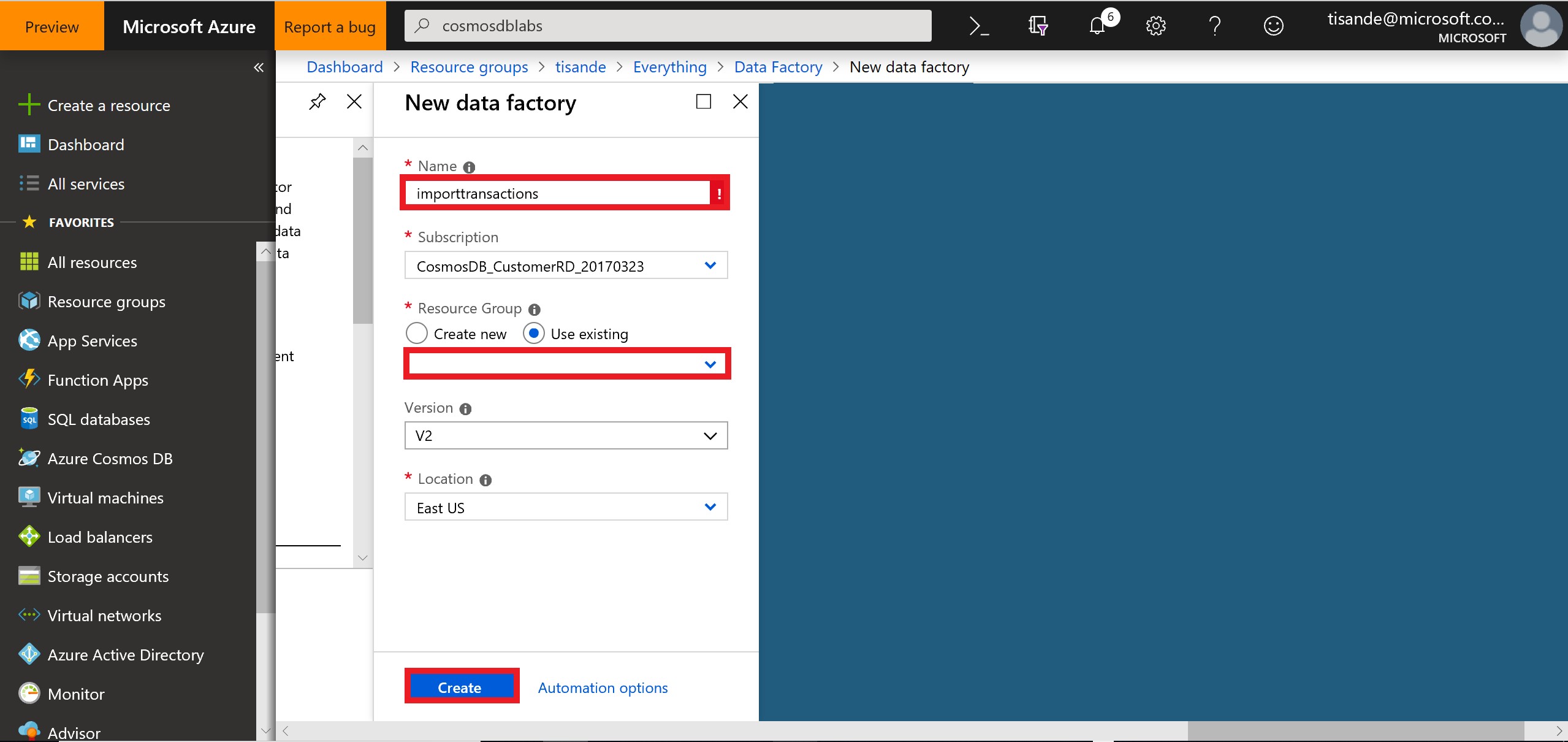
- Select Copy Data. We will be using ADF for a one-time copy of data from a source JSON file on Azure Blob Storage to a database in Cosmos DB’s SQL API. ADF can also be used for more frequent data transfer from Cosmos DB to other data stores.
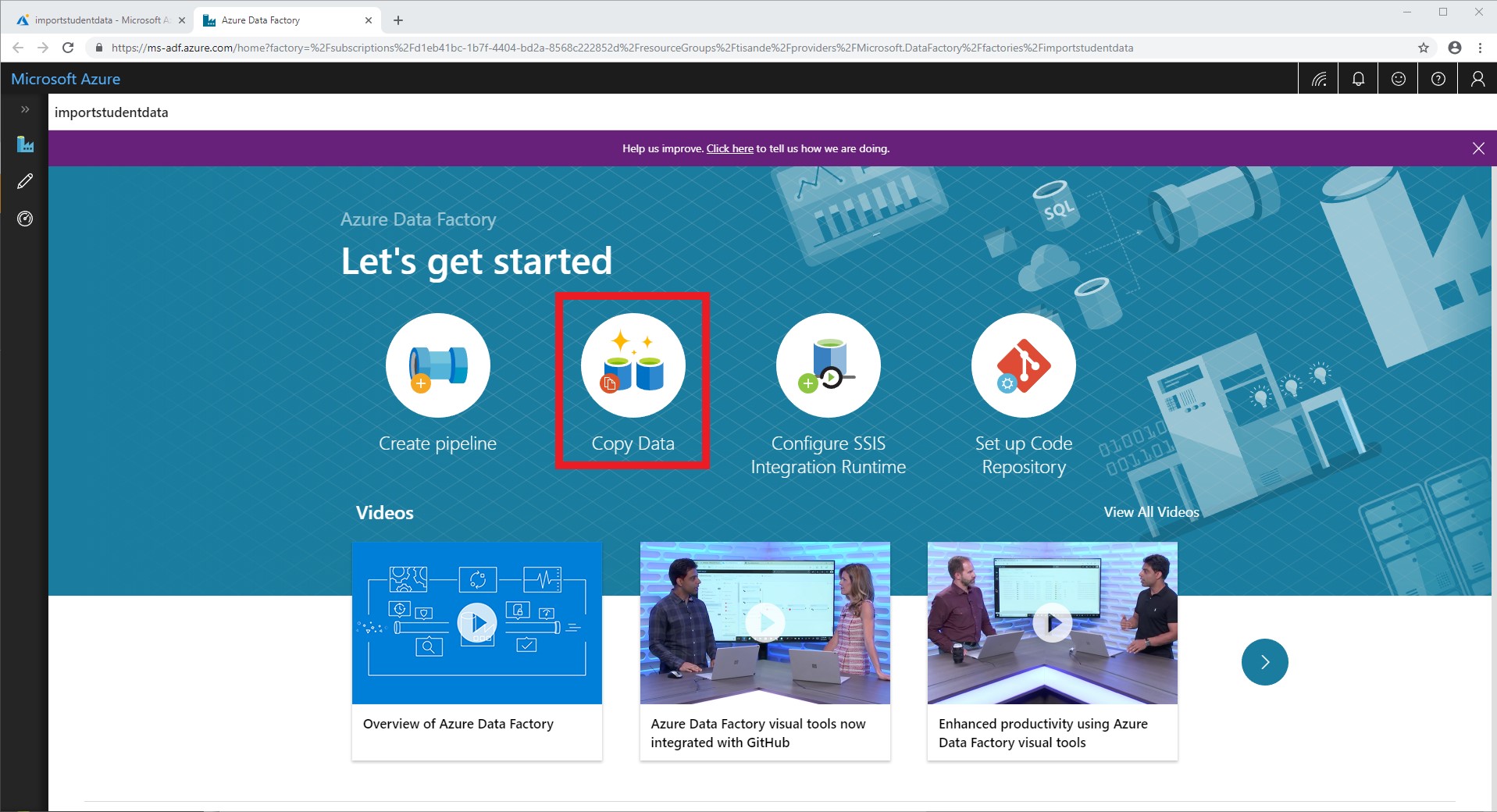
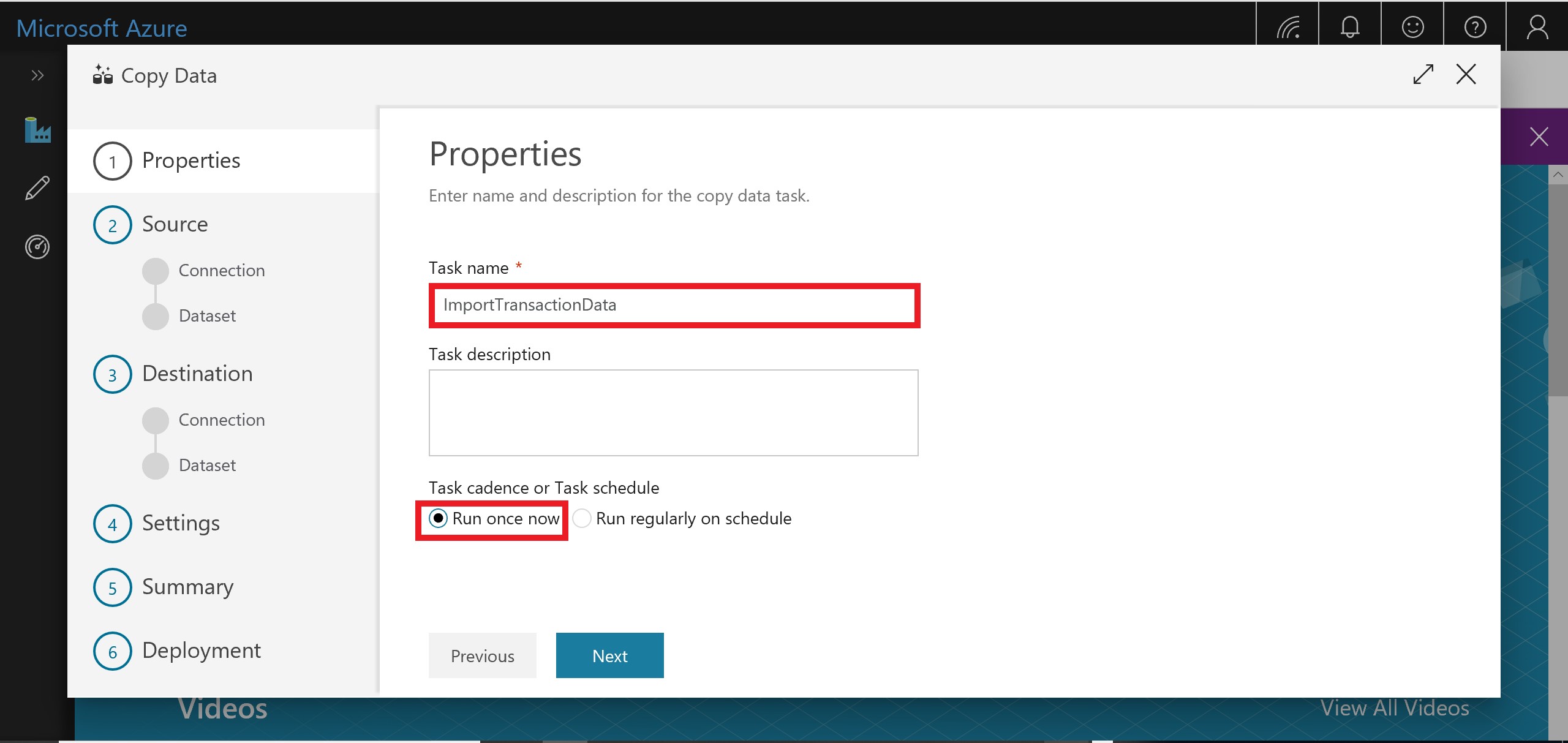
- Edit basic properties for this data copy. You should name the task ImportTransactionsData and select to Run once now.
-
Create a new connection and select Azure Blob Storage. We will import data from a json file on Azure Blob Storage. In addition to Blob Storage, you can use ADF to migrate from a wide variety of sources. We will not cover migration from these sources in this tutorial.
-
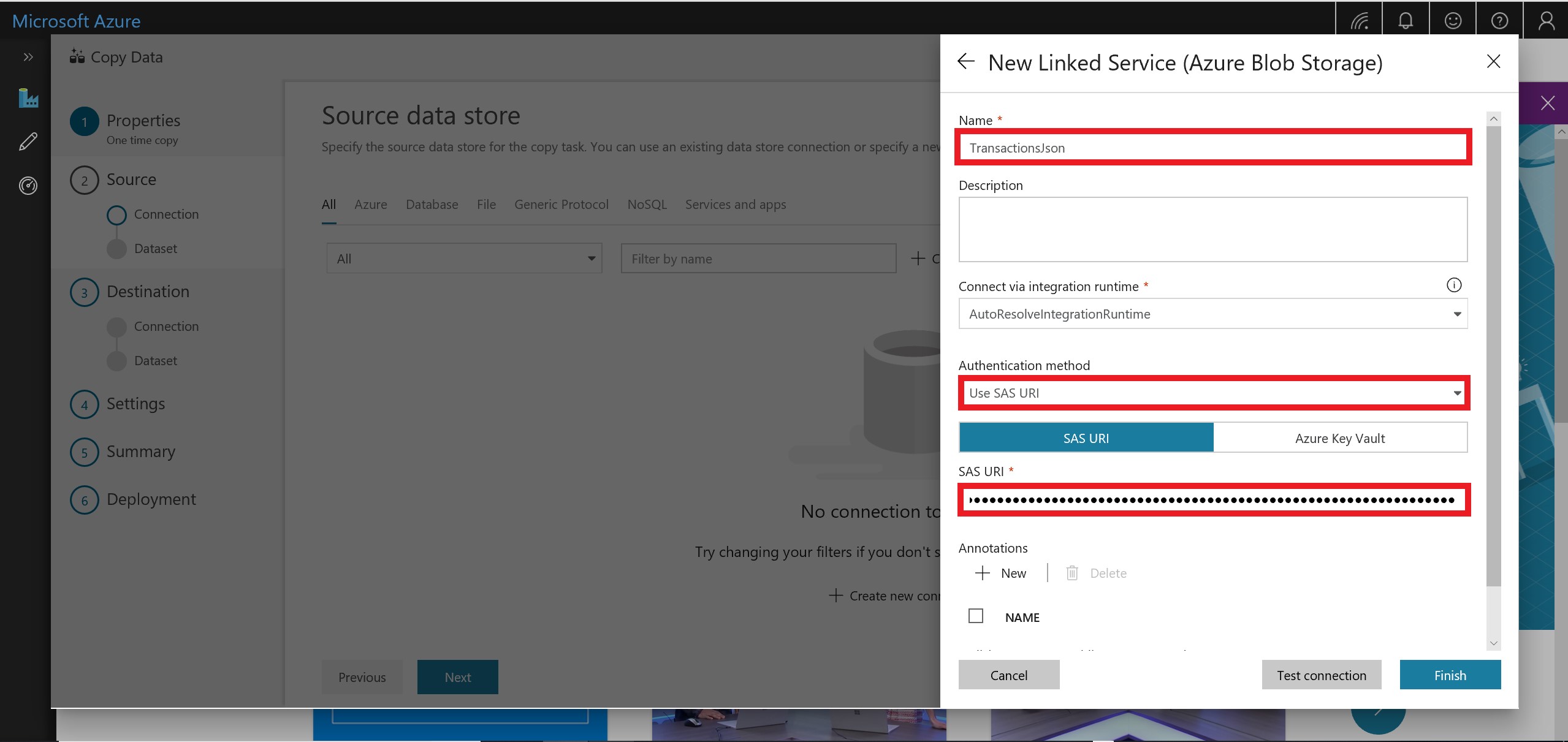
Name the source TransactionsJson and select Use SAS URI as the Authentication method. Please use the following SAS URI for read-only access to this Blob Storage container:
https://cosmoslabs.blob.core.windows.net/?sv=2018-03-28&ss=bfqt&srt=sco&sp=rl&se=2020-04-01T13:14:14Z&st=2018-11-06T06:14:14Z&spr=https&sig=8HltMx1smolMcSmOhfVdC3drxtmTkq2%2BfJ8574uK60A%3D
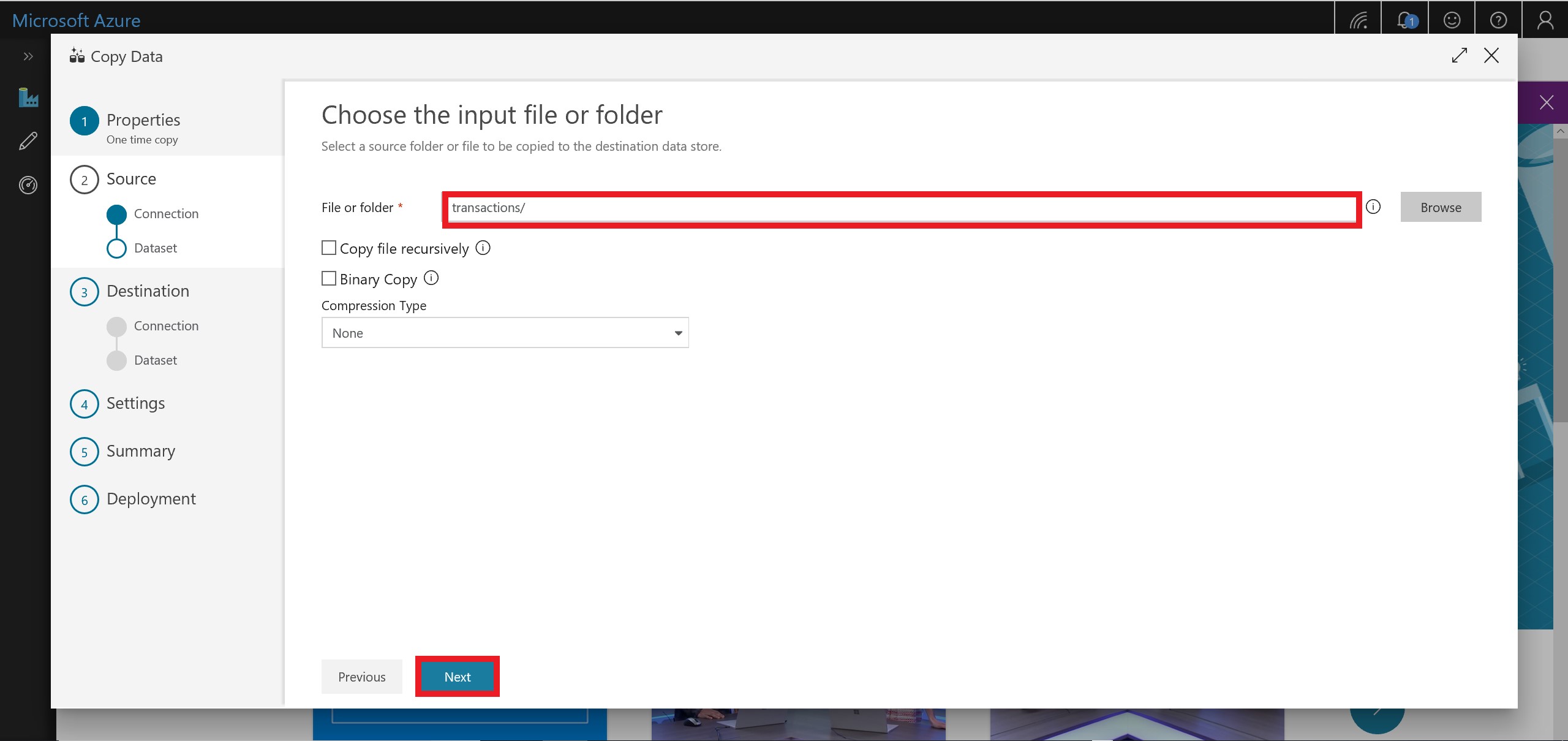
- Select the transactions folder.
-
Ensure that Copy file recursively and Binary Copy are not checked off. Also ensure that Compression Type is “none”.
-
ADF should auto-detect the file format to be JSON. You can also select the file format as JSON format. You should also make sure you select Array of Objects as the File pattern.
-
You have now successfully connected the Blob Storage container with the transactions.json file. You should select TransactionsJson as the source and click Next.
-
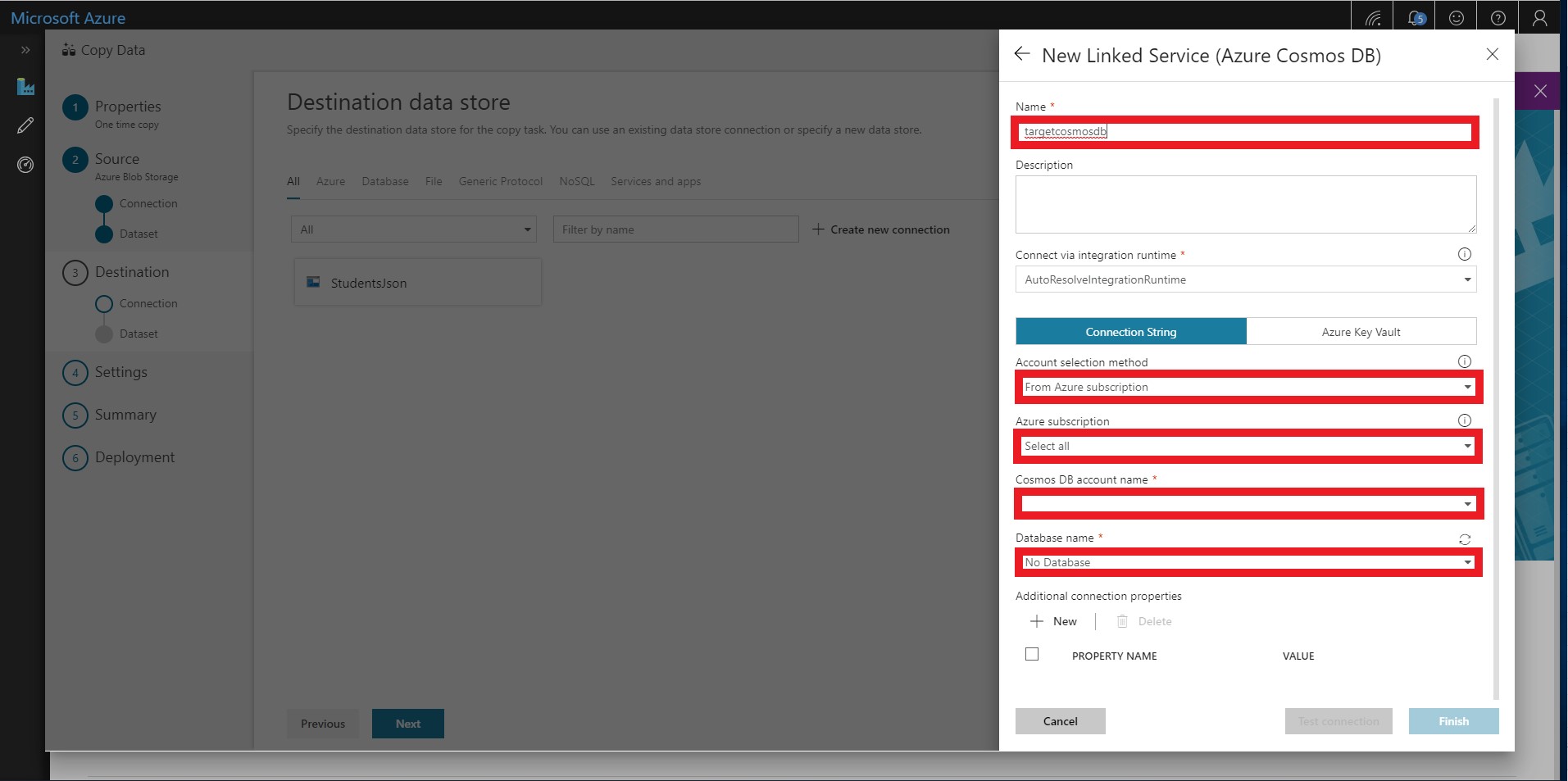
Add the Cosmos DB target data store by selecting Create new connection and selecting Azure Cosmos DB.
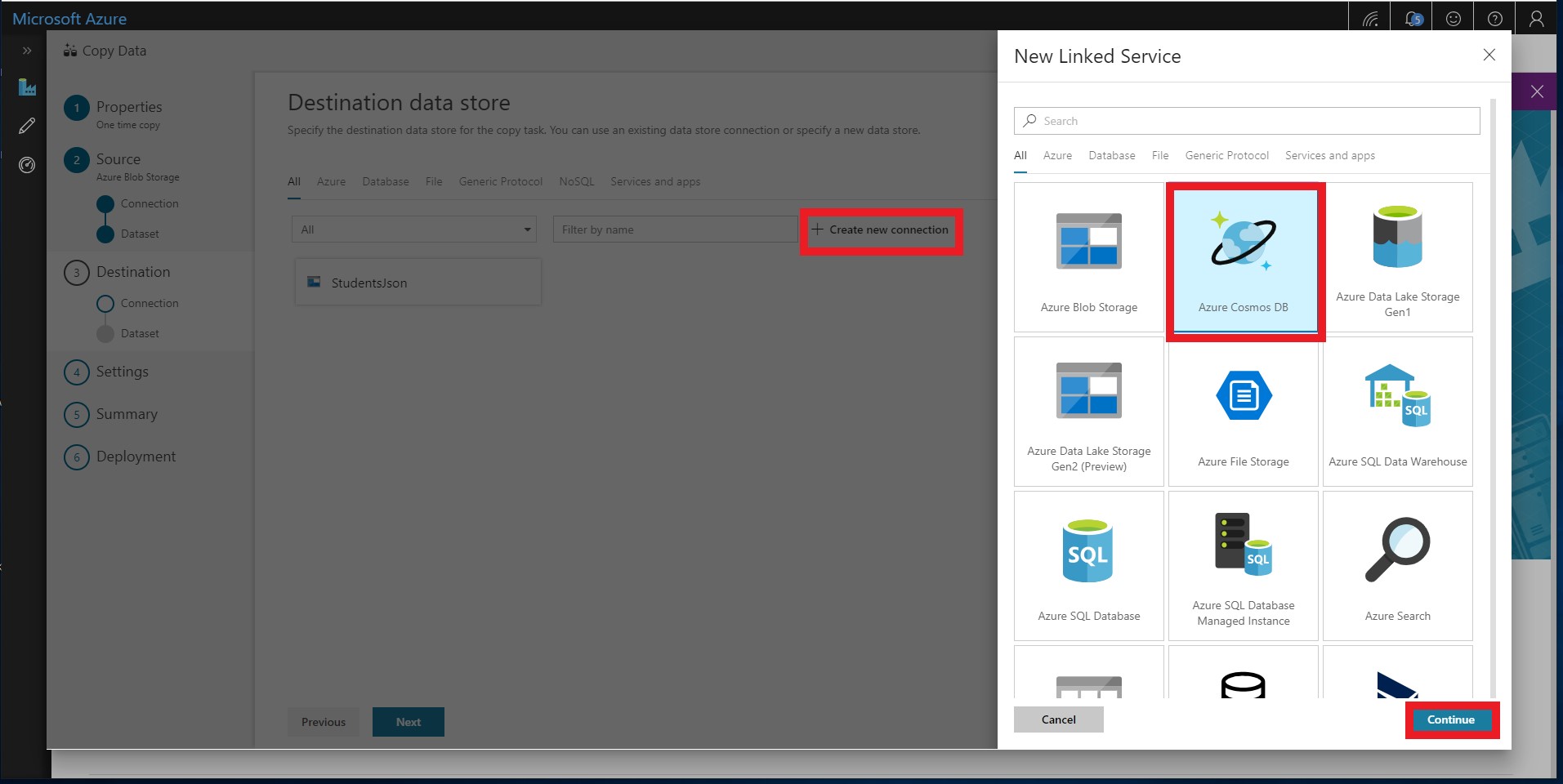
- Name the linked service targetcosmosdb and select your Azure subscription and Cosmos DB account. You should also select the Cosmos DB database that you created earlier.
-
Select your newly created targetcosmosdb connection as the Destination date store.
-
Select your collection from the drop-down menu. You will map your Blob storage file to the correct Cosmos DB collection.
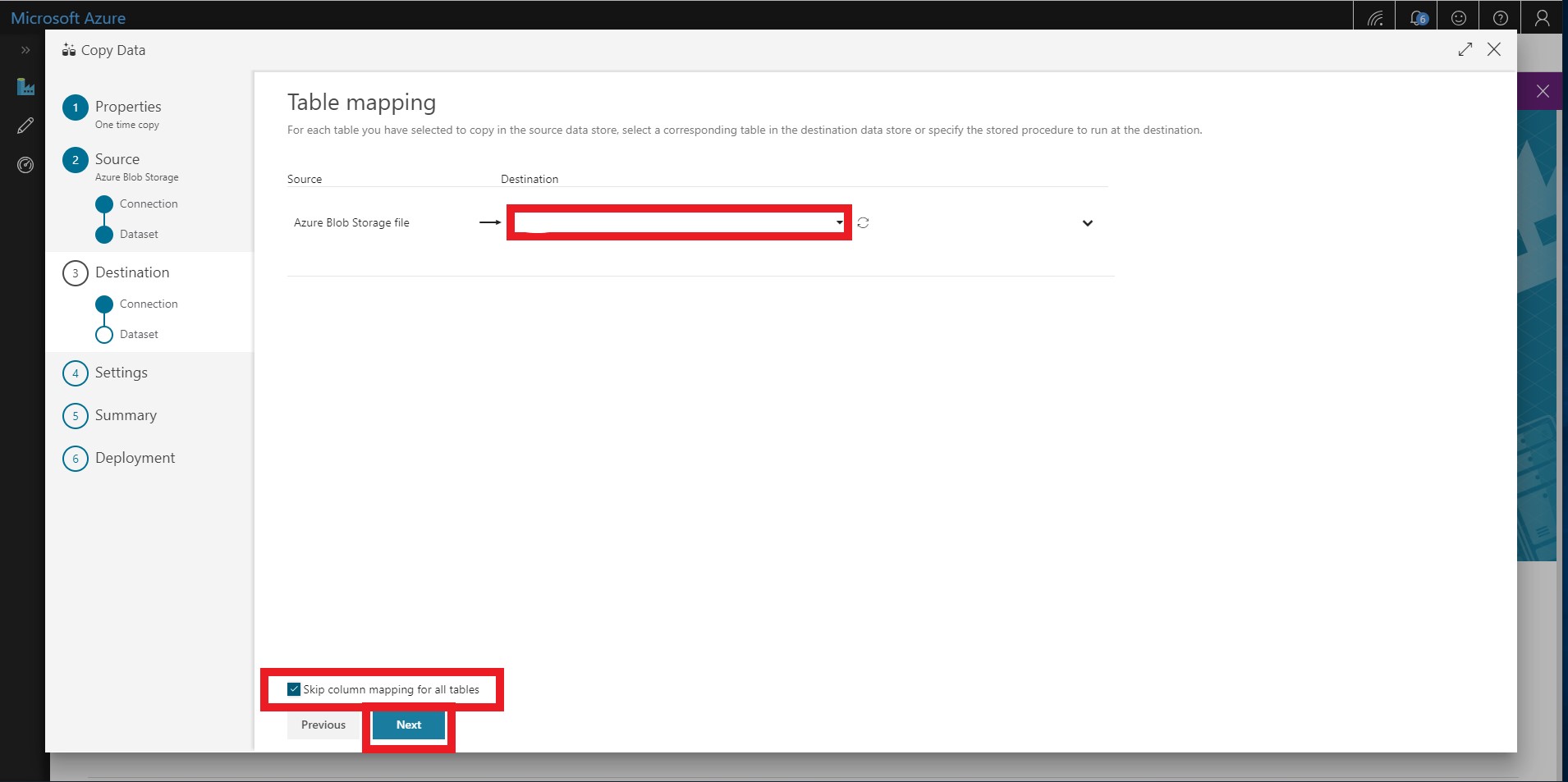
- You should have selected to skip column mappings in a previous step. Click through this screen.
- There is no need to change any settings. Click next.
- After deployment is complete, select Monitor.
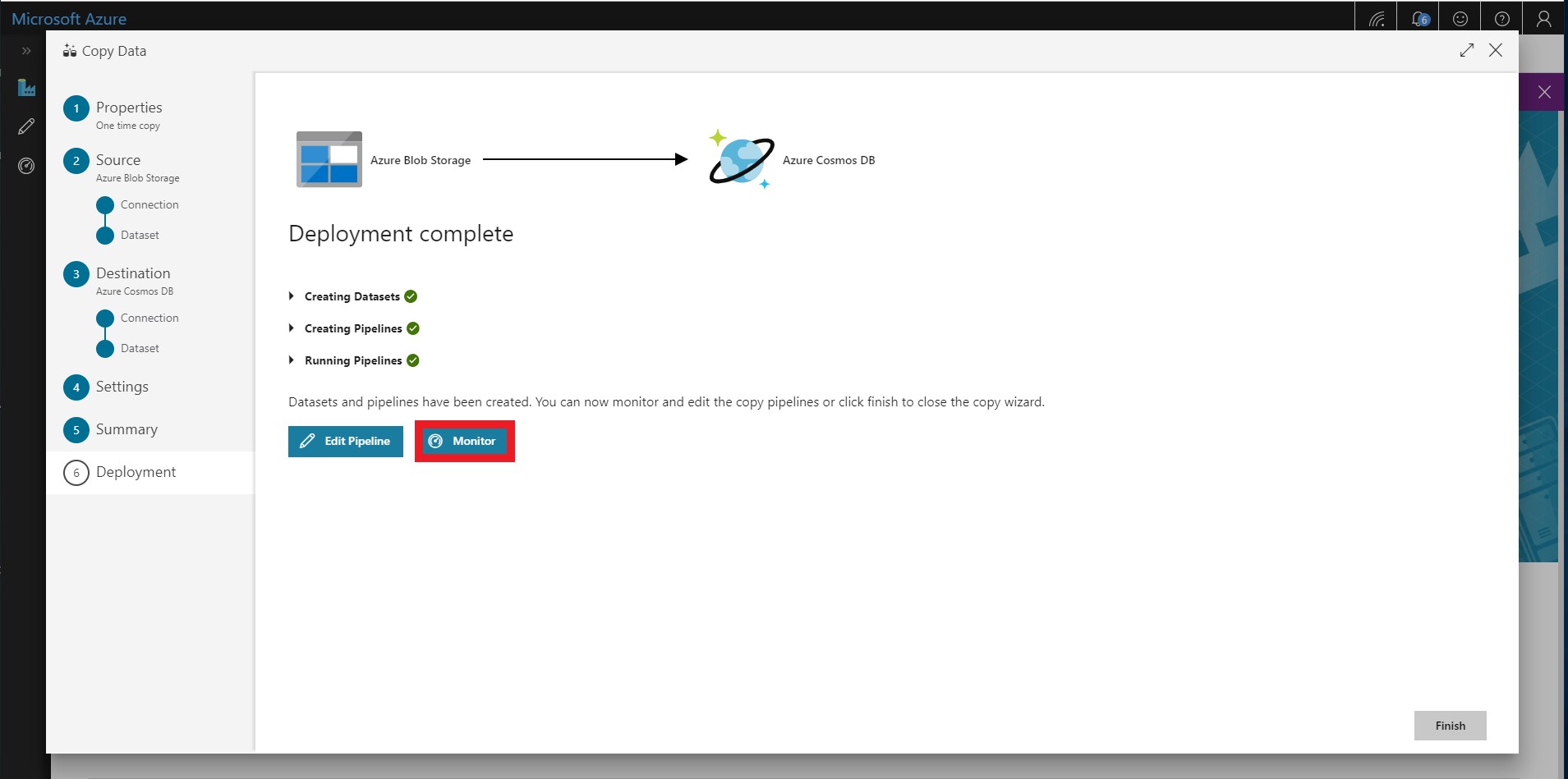
-
After a few minutes, refresh the page and the status for the ImportTransactions pipeline should be listed as Succeeded.
-
Once the import process has completed, close the ADF. You will later execute queries on your imported data.
Create a Java Project
-
On your local machine, create a new folder that will be used to contain the content of your Java project.
-
In the new folder, right-click the folder and select the Open with Code menu option.
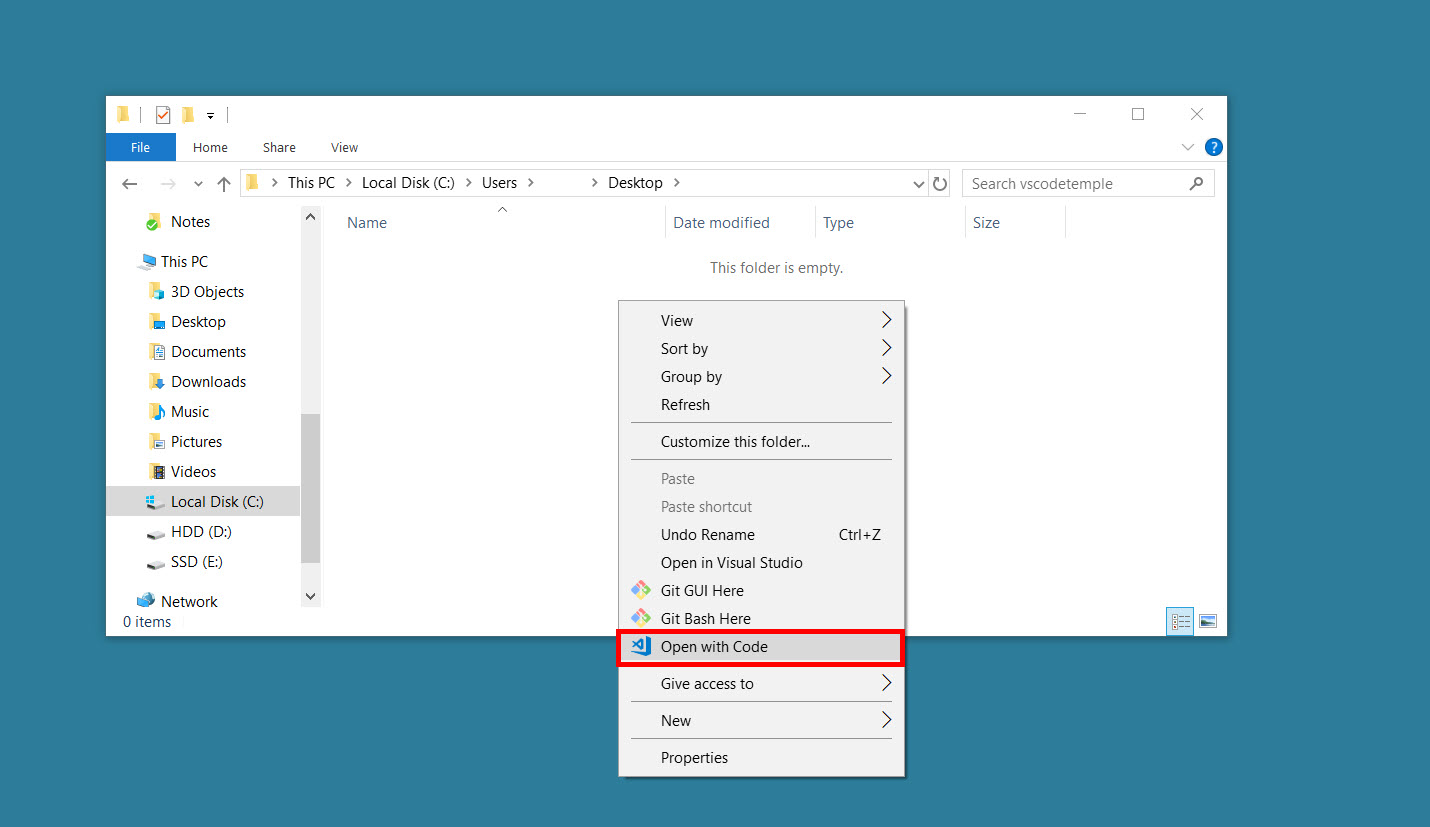
Alternatively, you can run a command prompt in your current directory and execute the
code .command. -
In the Visual Studio Code window that appears, right-click the Explorer under the folder you created, and select “Generate from Maven Archetype”:
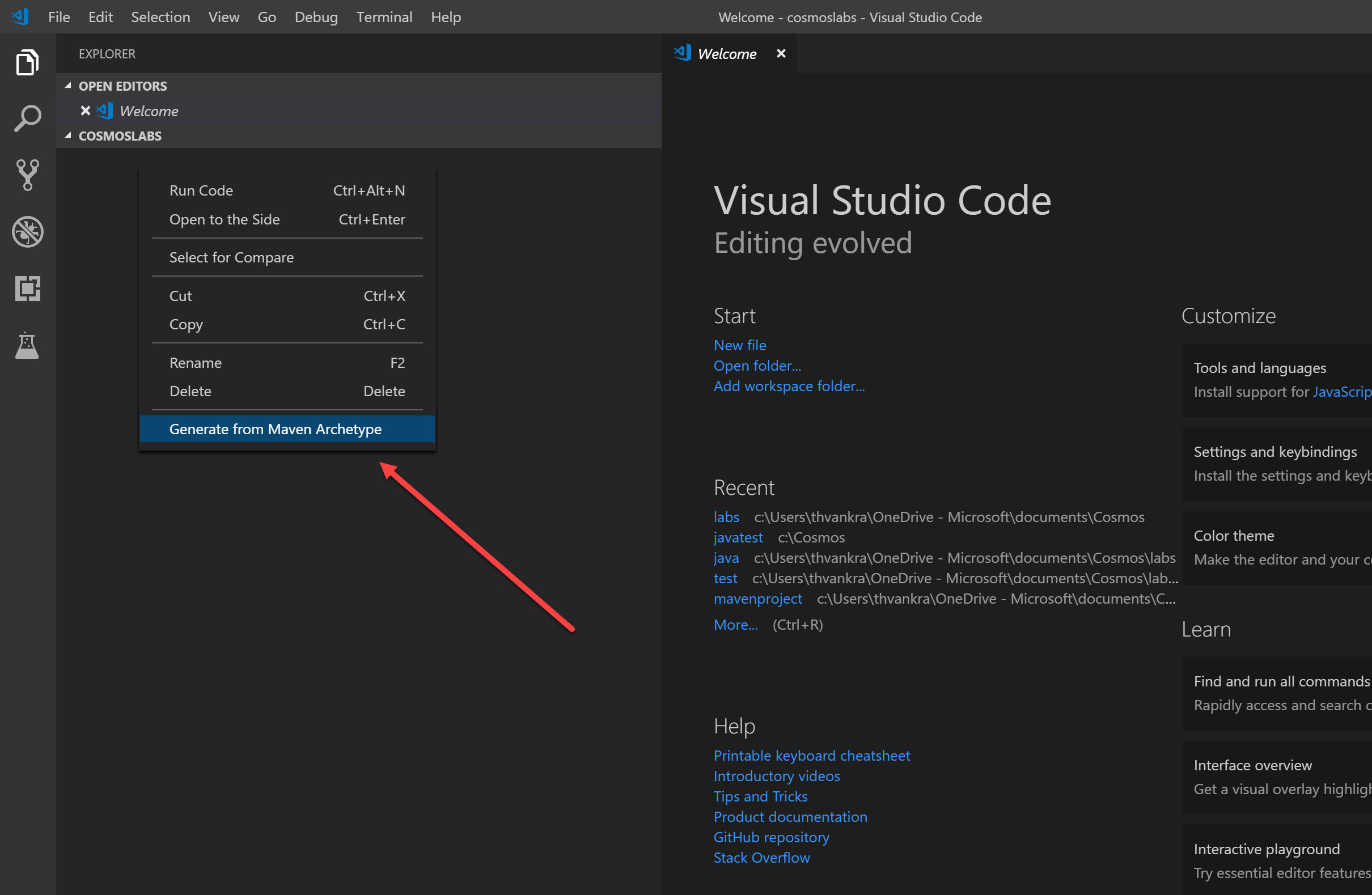
-
From the options that appear, select “maven-archetype-quickstart”, and then select the directory you created for the project when prompted. Maven will then prompt you to provide values for group id, artifact id, version, package. Fill these in when prompted and then confirm:
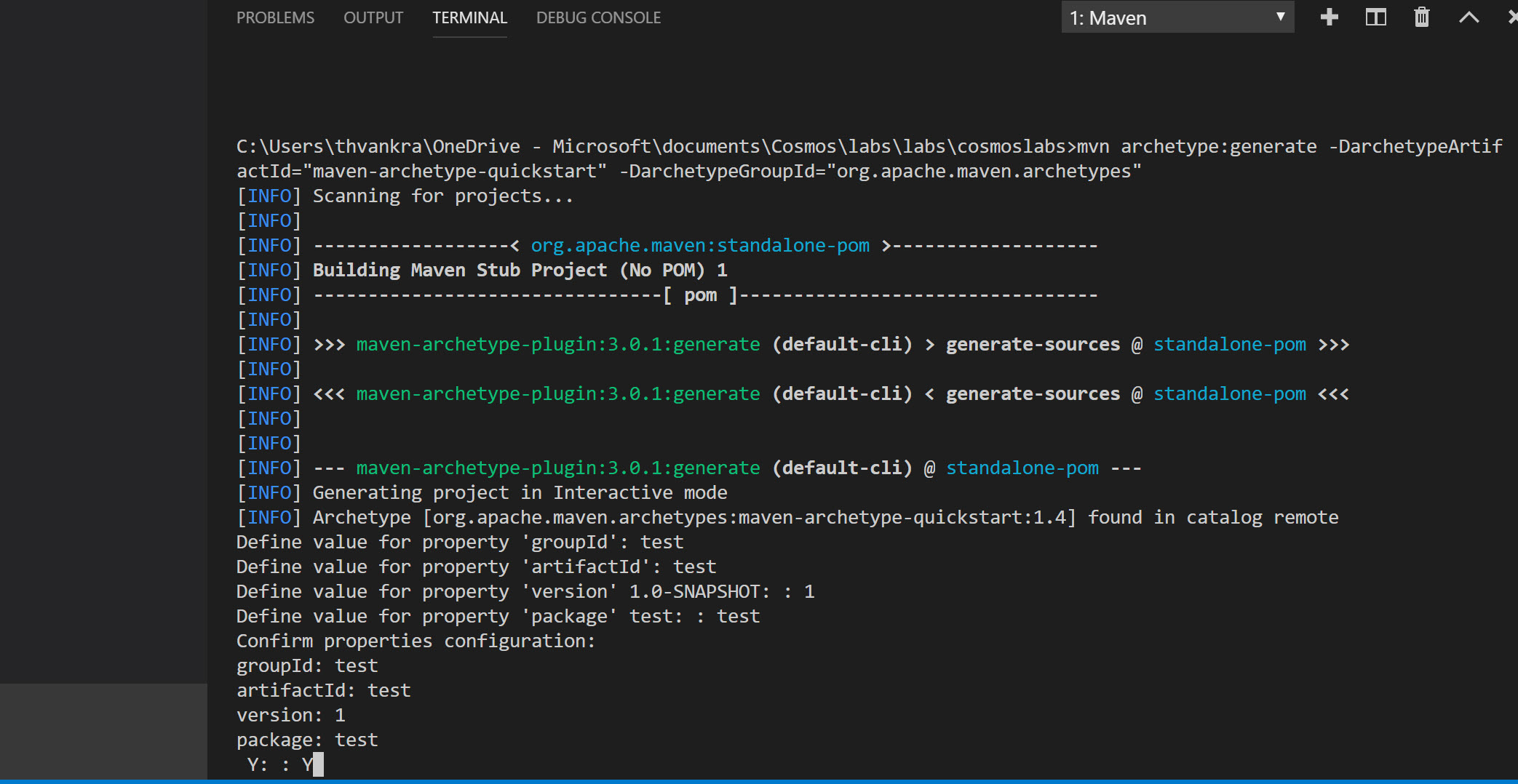
-
Once confirmed, Maven will create the project, and provide a sample App.java. For any Java class created in the project, VS Code’s Java Extension will provide “run” and “debug” links directly in the code. Clicking “run” will compile and run your Java code:
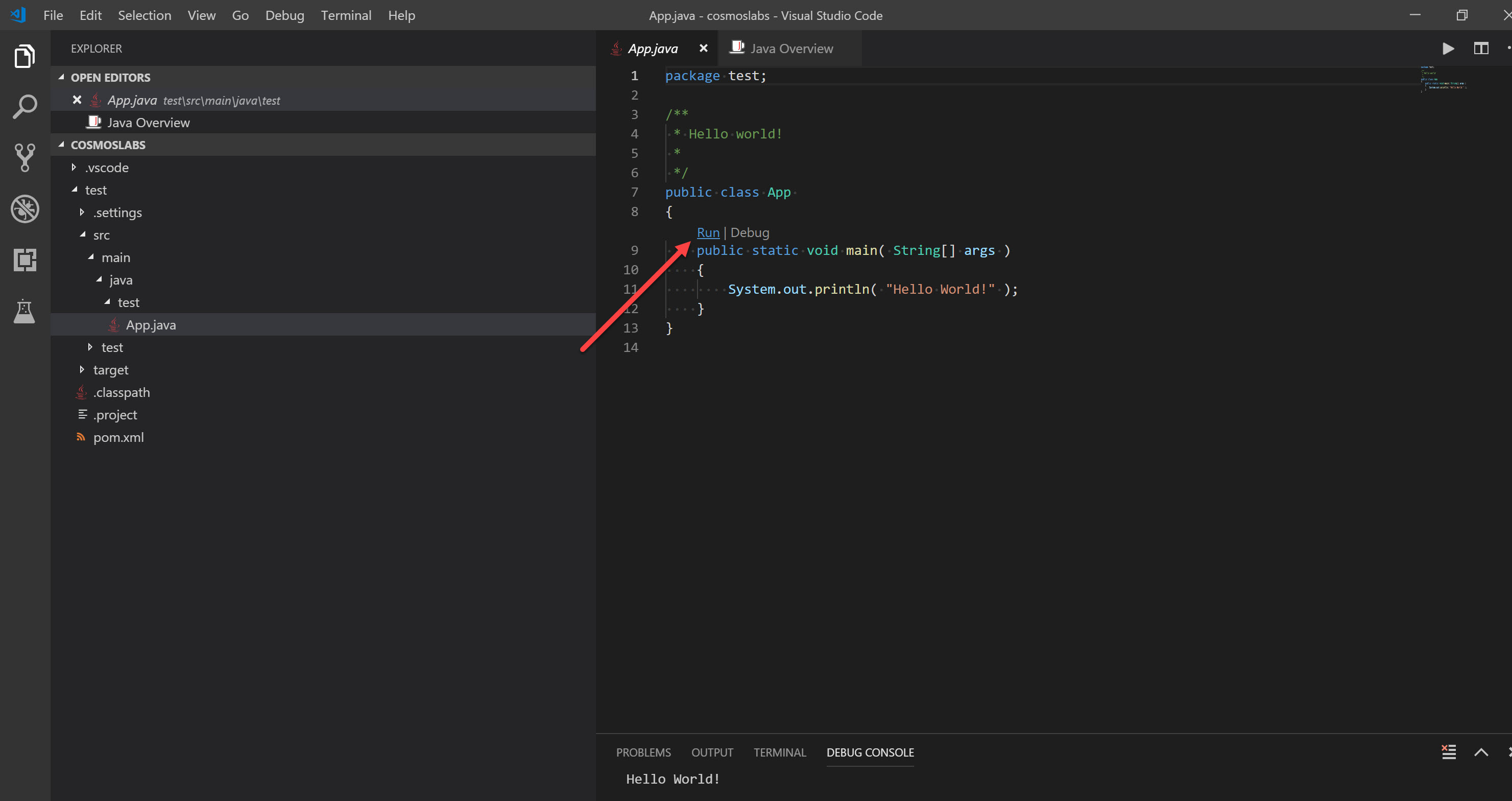
-
To add the Maven project dependancies required to work with Cosmos DB, you should add the following into the pom.xml file located at the bottom of your project, within the dependancies section:
<dependency> <groupId>com.microsoft.azure</groupId> <artifactId>azure-cosmosdb</artifactId> <version>2.4.3</version> </dependency> -
For this tutorial, you will also need to change the source and target compiler versions to Java 1.8, as we will use some lambda syntax which is only supported from Java 8 onwards. When finished, your pom.xml should look like the below:
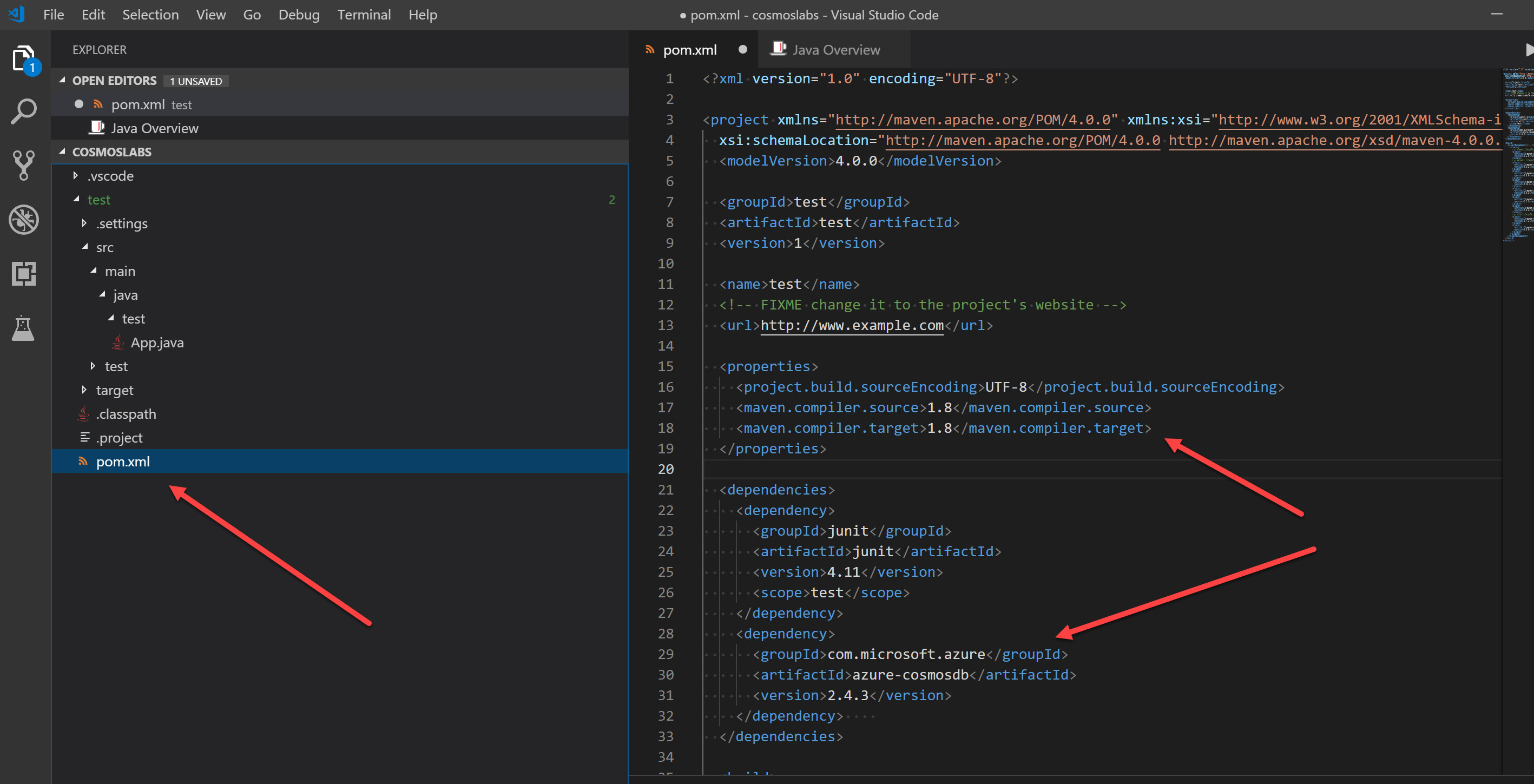
-
Once the changes are applied, ensure you click file -> save all. At this point, VS Code will recognise that you modified the pom.xml build file. Ensure that you accept the prompt to sync the dependancies:
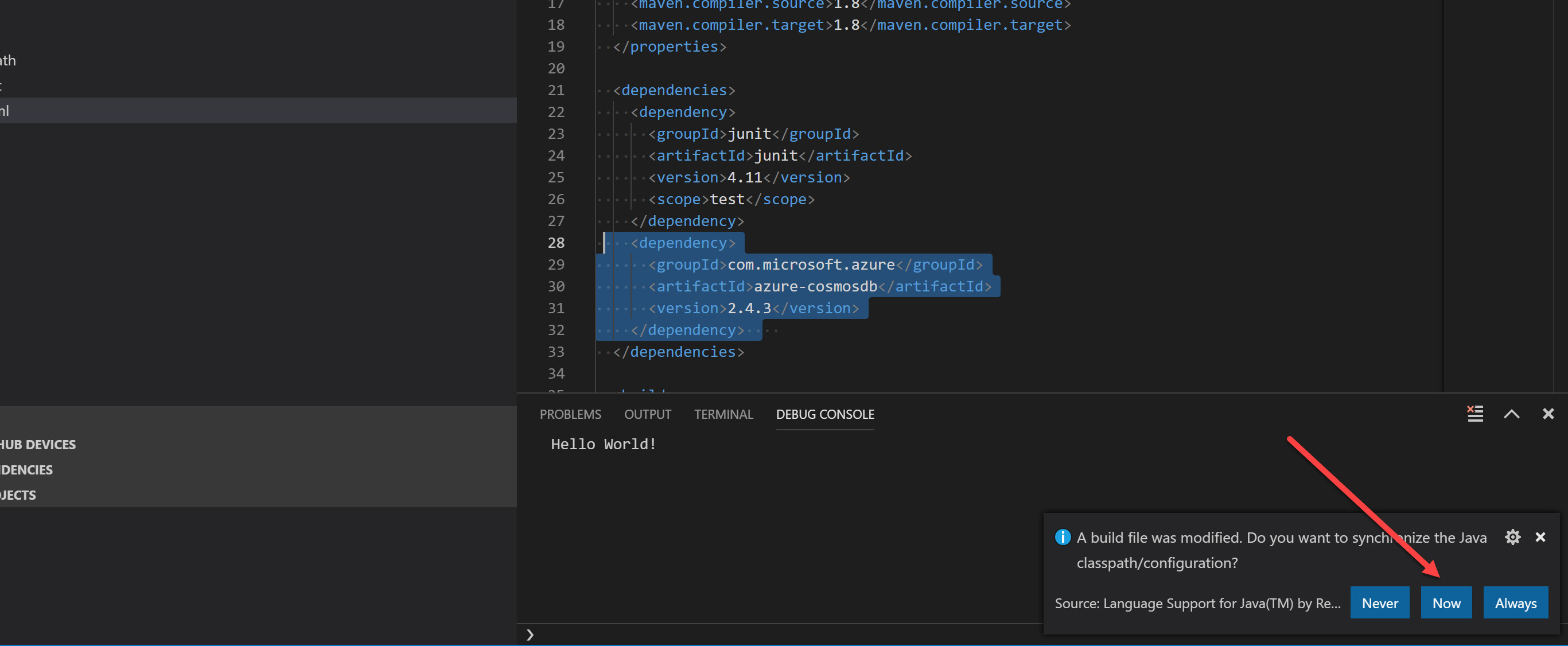
Once the dependencies are pulled down, you will be ready to start writing Java code for Cosmos DB.
Create AsyncDocumentClient Instance and Database
The AsyncDocumentClient class is the main “entry point” to using the SQL API in Azure Cosmos DB. We are going to create an instance of the AsyncDocumentClient class by passing in connection metadata as parameters of the class’ constructor. We will then use this class instance throughout the lab.
-
At the same level as the default “App.java” file that already exists, right click and create a new file called “Program.java”:
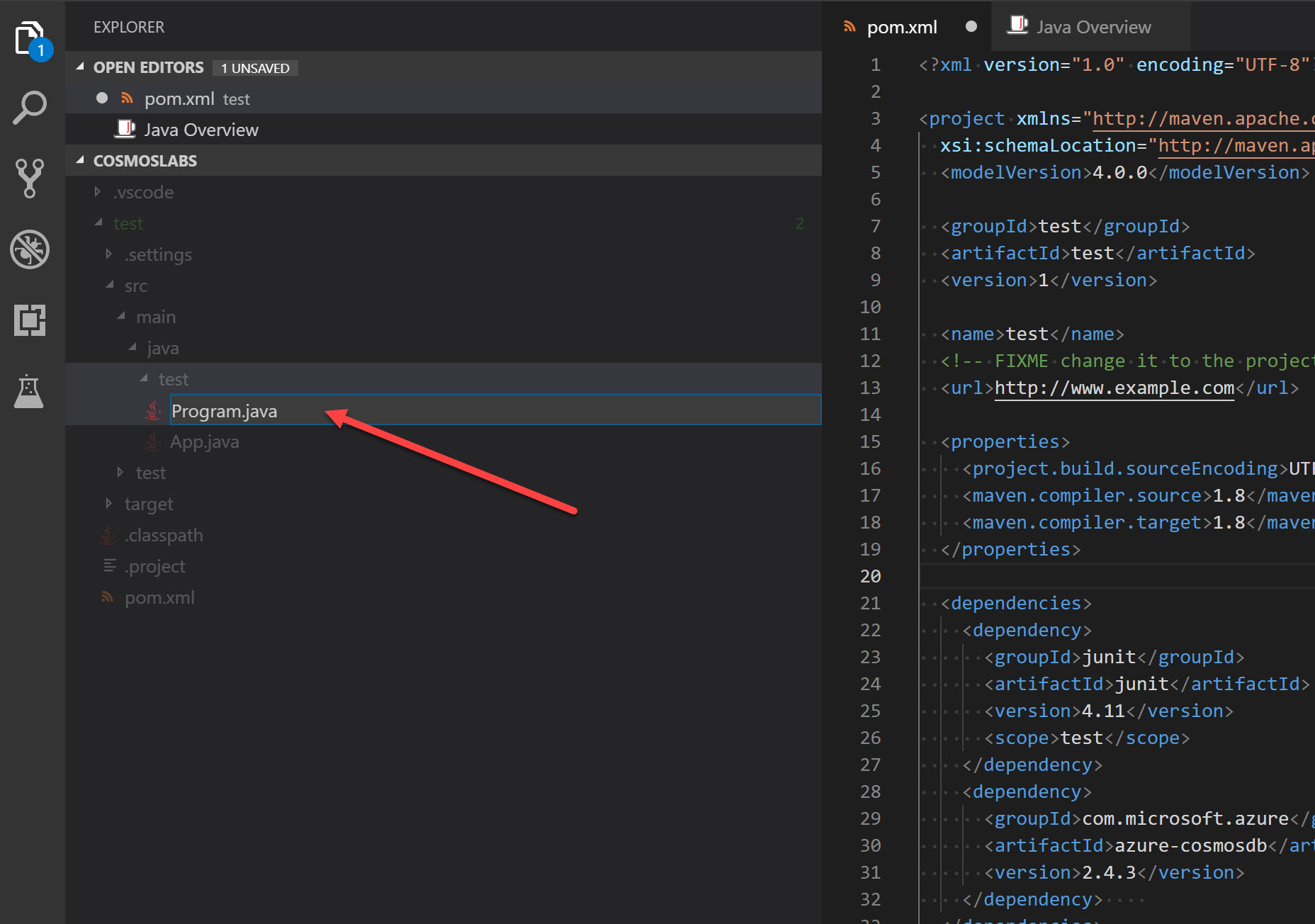
-
Within the Program.java editor tab, Add the following using blocks to the top of the editor:
package test; import java.util.ArrayList; import java.util.Collection; import java.util.List; import java.util.Collections; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutionException; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Future; import com.microsoft.azure.cosmosdb.AccessCondition; import com.microsoft.azure.cosmosdb.ConnectionPolicy; import com.microsoft.azure.cosmosdb.ConsistencyLevel; import com.microsoft.azure.cosmosdb.DataType; import com.microsoft.azure.cosmosdb.Database; import com.microsoft.azure.cosmosdb.DocumentClientException; import com.microsoft.azure.cosmosdb.DocumentCollection; import com.microsoft.azure.cosmosdb.IncludedPath; import com.microsoft.azure.cosmosdb.Index; import com.microsoft.azure.cosmosdb.IndexingPolicy; import com.microsoft.azure.cosmosdb.PartitionKeyDefinition; import com.microsoft.azure.cosmosdb.RequestOptions; import com.microsoft.azure.cosmosdb.ResourceResponse; import com.microsoft.azure.cosmosdb.rx.AsyncDocumentClient; import java.util.UUID; import rx.Observable; import rx.Scheduler; import rx.schedulers.Schedulers; -
Below the imports and package declaration, create a Program class in the Program.java file as below, with the following class code:
public class Program { private final ExecutorService executorService; private final Scheduler scheduler; private AsyncDocumentClient client; private final String databaseName = "FinancialDatabase"; private final String collectionId = "PeopleCollection"; private final String partitionKeyPath = "/type"; private final int throughPut = 1000; public Program() { executorService = Executors.newFixedThreadPool(100); scheduler = Schedulers.from(executorService); client = new AsyncDocumentClient.Builder().withServiceEndpoint("uri") .withMasterKeyOrResourceToken("key") .withConnectionPolicy(ConnectionPolicy.GetDefault()).withConsistencyLevel(ConsistencyLevel.Eventual) .build(); } public static void main(String[] args) { Program p = new Program(); try { p.createDatabase(); System.out.println(String.format("Database created, please hold while resources are released")); //create collection... p.createMultiPartitionCollection(); } catch (Exception e) { System.err.println(String.format("DocumentDB GetStarted failed with %s", e)); } finally { System.out.println("close the client"); p.close(); } System.exit(0); } private void createDatabase() throws Exception { String databaseLink = String.format("/dbs/%s", databaseName); Observable<ResourceResponse<Database>> databaseReadObs = client.readDatabase(databaseLink, null); Observable<ResourceResponse<Database>> databaseExistenceObs = databaseReadObs.doOnNext(x -> { System.out.println("database " + databaseName + " already exists."); }).onErrorResumeNext(e -> { if (e instanceof DocumentClientException) { DocumentClientException de = (DocumentClientException) e; if (de.getStatusCode() == 404) { System.out.println("database " + databaseName + " doesn't exist," + " creating it..."); Database dbDefinition = new Database(); dbDefinition.setId(databaseName); return client.createDatabase(dbDefinition, null); } } System.err.println("Reading database " + databaseName + " failed."); return Observable.error(e); }); databaseExistenceObs.toCompletable().await(); System.out.println("Checking database " + databaseName + " completed!\n"); } private DocumentCollection getMultiPartitionCollectionDefinition() { DocumentCollection collectionDefinition = new DocumentCollection(); collectionDefinition.setId(collectionId); PartitionKeyDefinition partitionKeyDefinition = new PartitionKeyDefinition(); List<String> paths = new ArrayList<>(); paths.add(partitionKeyPath); partitionKeyDefinition.setPaths(paths); collectionDefinition.setPartitionKey(partitionKeyDefinition); // Set indexing policy to be range range for string and number IndexingPolicy indexingPolicy = new IndexingPolicy(); Collection<IncludedPath> includedPaths = new ArrayList<>(); IncludedPath includedPath = new IncludedPath(); includedPath.setPath("/*"); Collection<Index> indexes = new ArrayList<>(); Index stringIndex = Index.Range(DataType.String); stringIndex.set("precision", -1); indexes.add(stringIndex); Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy); return collectionDefinition; } public void createMultiPartitionCollection() throws Exception { RequestOptions multiPartitionRequestOptions = new RequestOptions(); multiPartitionRequestOptions.setOfferThroughput(throughPut); String databaseLink = String.format("/dbs/%s", databaseName); Observable<ResourceResponse<DocumentCollection>> createCollectionObservable = client.createCollection( databaseLink, getMultiPartitionCollectionDefinition(), multiPartitionRequestOptions); final CountDownLatch countDownLatch = new CountDownLatch(1); createCollectionObservable.single() // We know there is only single result .subscribe(collectionResourceResponse -> { System.out.println(collectionResourceResponse.getActivityId()); countDownLatch.countDown(); }, error -> { System.err.println( "an error occurred while creating the collection: actual cause: " + error.getMessage()); countDownLatch.countDown(); }); System.out.println("creating collection..."); countDownLatch.await(); } public void close() { executorService.shutdown(); client.close(); } } -
Save all of your open editor tabs, and click run (this should give you a message saying that the database already exists as you should have created it earlier in the lab, but the collection will be created)
-
Click the 🗙 symbol to close the terminal pane.
-
Close all open editor tabs.
Examining Response Headers
Azure Cosmos DB returns various response headers that can give you more metadata about your request and what operations occured on the server-side. The Java Async SDK exposes many of these headers to you as properties of the ResourceResponse<> class.
Observe RU Charge for Large Document
To help generate random data in the documents, we are going to use a java library called “javafaker”, so if not already present, you will need to add the following to your pom.xml file, located at the bottom of your project, within the dependancies section (ensure you accept the “synchronize the Java classpath/configuration” warning if you have not accepted this permanently):
<dependency>
<groupId>com.github.javafaker</groupId>
<artifactId>javafaker</artifactId>
<version>0.17.2</version>
</dependency>
-
Create a file in your directory called PersonDetail.java, and copy the following code (be sure to specify the correct classpath for the package declaration):
package testpackage; import java.text.DecimalFormat; import java.util.ArrayList; import java.util.Random; import com.github.javafaker.Faker; import com.microsoft.azure.cosmosdb.Document; public class PersonDetail { Faker faker = new Faker(); ArrayList<Document> documentDefinitions = new ArrayList<>(); public PersonDetail(int number, int childnumber) throws NumberFormatException { for (int i= 0; i < number;i++){ ArrayList<Document> children = new ArrayList<>(); for (int j= 0; j < childnumber;j++){ Document child= new Document(); child.set("firstName", faker.name().firstName()); child.set("lastName", faker.name().lastName()); children.add(child); } Document spouse= new Document(); spouse.set("firstName", faker.name().firstName()); spouse.set("lastName", faker.name().lastName()); Document relatives = new Document(); relatives.set("children", children); relatives.set("spouse", spouse); Document documentDefinition = new Document(); Document address = new Document(); address.set("Street", faker.address().buildingNumber()+" "+faker.address().streetName()); address.set("City", faker.address().city()); address.set("Country", faker.address().country()); documentDefinition.set("DateOfBirth", faker.date().birthday()); documentDefinition.set("firstName", faker.name().firstName()); documentDefinition.set("lastName", faker.name().lastName()); documentDefinition.set("PhoneNumber", faker.phoneNumber().phoneNumber()); documentDefinition.set("Company", faker.company().name()); documentDefinition.set("Address", address); documentDefinition.set("type", "personofinterest"); documentDefinition.set("type", "personofinterest"); documentDefinition.set("Relatives", relatives); documentDefinitions.add(documentDefinition); } } }This class will generate a fictional person with randomized properties. Here’s an example of a fictional person JSON document:
{ "DateOfBirth": -6296557022, "firstName": "Torrie", "lastName": "Douglas", "PhoneNumber": "(000) 540-9208 x53930", "Company": "Schimmel, Langworth and Heaney", "Address": { "Street": "156 Phebe Canyon", "City": "Smithamburgh", "Country": "Eritrea" }, "type": "personofinterest", "Relatives": { "children": [ { "firstName": "Neta", "lastName": "Block" }, { "firstName": "Wilbert", "lastName": "Schamberger" }, { "firstName": "Alejandro", "lastName": "McLaughlin" }, { "firstName": "Donnetta", "lastName": "Cole" } ], "spouse": { "firstName": "Jewell", "lastName": "Crooks" } } } -
Below the main method in your Program class, copy the following new method:
public void createDocument() throws Exception { ArrayList<Document> documents = new PersonDetail(1, 1).documentDefinitions; for (Document document : documents) { // Create a document Observable<ResourceResponse<Document>> createDocumentObservable = client .createDocument("dbs/" + databaseName + "/colls/" + collectionId, document, null, false); Observable<Double> totalChargeObservable = createDocumentObservable.map(ResourceResponse::getRequestCharge) // Map to request charge .reduce((totalCharge, charge) -> totalCharge + charge); // Sum up all the charges final CountDownLatch completionLatch = new CountDownLatch(1); // Subscribe to the total request charge observable totalChargeObservable.subscribe(totalCharge -> { // Print the total charge System.out.println("RU charge: "+totalCharge); completionLatch.countDown(); }, e -> completionLatch.countDown()); completionLatch.await(); } } -
Locate the Main method in your Program class and replace it with the following:
public static void main(String[] args) { Program p = new Program(); try { p.createDocument(); System.out.println("finished"); } catch (Exception e) { System.err.println(String.format("failed with %s", e)); } System.exit(0); } -
Save all of your open editor tabs, and click run.
-
Observe the results of the console project.
You should see the document creation operation use approximately 11 RUs.
-
Click the 🗙 symbol to close the terminal pane.
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmosgroup-lab Resource Group.
-
In the cosmosgroup-lab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node and then observe select the PeopleCollection node.
-
Click the New SQL Query button at the top of the Data Explorer section.
-
In the query tab, replace the contents of the query editor with the following SQL query:
SELECT TOP 2 * FROM coll ORDER BY coll._ts DESCThis query will return the latest two documents added to your collection.
-
Click the Execute Query button in the query tab to run the query.
-
In the Results pane, observe the results of your query.
-
Return to the currently open Visual Studio Code editor containing your Java project.
-
In the Visual Studio Code window, double-click the Program.java file to open an editor tab for the file.
-
To view the RU charge for inserting a very large document, we will increase the number of children under the “Relatives” section generated by the PersonDetail class. Locate the following line of code in the createDocument method:
ArrayList<Document> documents = new PersonDetail(1, 1).documentDefinitions; -
Replace it with the following:
ArrayList<Document> documents = new PersonDetail(1, 100).documentDefinitions;This will generate a document with 100 children in the Relatives section
-
Save all of your open editor tabs, and click run.
-
Observe the results of the console project.
You should see this new operation require far more RUs than the simple JSON document.
-
Click the 🗙 symbol to close the terminal pane.
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmosgroup-lab Resource Group.
-
In the cosmosgroup-lab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node and then observe select the PeopleCollection node.
-
Click the New SQL Query button at the top of the Data Explorer section.
-
In the query tab, replace the contents of the query editor with the following SQL query:
SELECT * FROM coll WHERE IS_DEFINED(coll.Relatives)This query will return the only document in your collection with a property named Children.
-
Click the Execute Query button in the query tab to run the query.
-
In the Results pane, observe the results of your query.
Tune Index Policy
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node, expand the PeopleCollection node, and then select the Scale & Settings option.
-
In the Settings section, locate the Indexing Policy field and observe the current default indexing policy:
{ "indexingMode": "consistent", "automatic": true, "includedPaths": [ { "path": "/*", "indexes": [] } ], "excludedPaths": [ { "path": "/\"_etag\"/?" } ] }This policy will index all paths in your JSON document. This policy implements maximum percision (-1) for both numbers (max 8) and strings (max 100) paths. This policy will also index spatial data.
-
Replace the indexing policy with a new policy that removes the
/Relatives/*path from the index:{ "indexingMode": "consistent", "automatic": true, "includedPaths": [ { "path": "/*", "indexes": [] } ], "excludedPaths": [ { "path": "/\"_etag\"/?" }, { "path":"/Relatives/*" } ] }This new policy will exclude the
/Relatives/*path from indexing effectively removing the Children property of your large JSON document from the index. -
Click the Save button at the top of the section to persist your new indexing policy and “kick off” a transformation of the collection’s index.
-
Click the New SQL Query button at the top of the Data Explorer section.
-
In the query tab, replace the contents of the query editor with the following SQL query:
SELECT * FROM coll WHERE IS_DEFINED(coll.Relatives) -
Click the Execute Query button in the query tab to run the query.
You will see immediately that you can still determine if the /Relatives path is defined.
-
In the query tab, replace the contents of the query editor with the following SQL query:
SELECT * FROM coll WHERE IS_DEFINED(coll.Relatives) ORDER BY coll.Relatives.Spouse.FirstName -
Click the Execute Query button in the query tab to run the query.
This query will fail immediately since this property is not indexed.
-
Return to the currently open Visual Studio Code editor containing your Java project, and run your Program class again to create another document.
-
Observe the results of the console project.
You should see a difference in the number of RUs required to create this document. This is due to the indexer skipping the paths you excluded.
-
Click the 🗙 symbol to close the terminal pane.
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmosgroup-lab Resource Group.
-
In the cosmosgroup-lab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node, expand the PeopleCollection node, and then select the Scale & Settings option.
-
In the Settings section, locate the Indexing Policy field and replace the indexing policy with a new policy:
{ "indexingMode": "consistent", "automatic": true, "includedPaths": [ { "path":"/*", "indexes":[ { "kind": "Range", "dataType": "String", "precision": -1 }, { "kind": "Range", "dataType": "Number", "precision": -1 } ] } ] }This new policy removes the
/Relatives/*path from the excluded path list so that the path can be indexed again. -
Click the Save button at the top of the section to persist your new indexing policy and “kick off” a transformation of the collection’s index.
-
Click the New SQL Query button at the top of the Data Explorer section.
-
In the query tab, replace the contents of the query editor with the following SQL query:
SELECT * FROM coll WHERE IS_DEFINED(coll.Relatives) ORDER BY coll.Relatives.Spouse.FirstName -
Click the Execute Query button in the query tab to run the query.
This query should now work. If you see an empty result set, this is because the indexer has not finished indexing all of the documents in the collection. Simply rerun the query until you see a non-empty result set.
Implement Upsert using Response Status Codes
-
Add the following method to your Program class:
public void documentUpsert_Async() throws Exception { // Create a document Document doc = new Document(String.format("{ 'id': 'example.document', 'type': 'upsertsample'}", UUID.randomUUID().toString(), 1)); ConnectionPolicy connPol = new ConnectionPolicy(); connPol.setConnectionMode(ConnectionMode.Direct); AsyncDocumentClient docClient = new AsyncDocumentClient.Builder() .withServiceEndpoint("uri") .withMasterKeyOrResourceToken("key") .withConnectionPolicy(connPol) .withConsistencyLevel(ConsistencyLevel.Session) .build(); docClient.createDocument("dbs/" + databaseName + "/colls/" + collectionId, doc, null, false); // Upsert the existing document Document upsertingDocument = new Document( String.format("{ 'id': 'example.document', 'type': 'upsertsample', 'new-prop' : '2'}", doc.getId(), 1)); Observable<ResourceResponse<Document>> upsertDocumentObservable = client .upsertDocument("dbs/" + databaseName + "/colls/" + collectionId, upsertingDocument, null, false); List<ResourceResponse<Document>> capturedResponse = Collections .synchronizedList(new ArrayList<>()); upsertDocumentObservable.subscribe(resourceResponse -> { capturedResponse.add(resourceResponse); }); Thread.sleep(4000); } -
Replace the call in your main method, to call the above method, as below:
public static void main(String[] args) { Program p = new Program(); try { p.createDocument(); System.out.println("finished"); } catch (Exception e) { System.err.println(String.format("failed with %s", e)); } System.exit(0); } -
Save all of your open editor tabs, and click run
The initial createDocument call within the new method creates a document, and we are then “upserting” a document with the same id, the server-side operation will be to update the existing document with the same id, and you will see the added attributes.
-
Click the 🗙 symbol to close the terminal pane.
Troubleshooting Requests
First, you will use the Java SDK to issue request beyond the assigned capacity for a container. Request unit consumption is evaluated at a per-second rate. For applications that exceed the provisioned request unit rate, requests are rate-limited until the rate drops below the provisioned throughput level. When a request is rate-limited, the server preemptively ends the request with an HTTP status code of 429 RequestRateTooLargeException and returns the x-ms-retry-after-ms header. The header indicates the amount of time, in milliseconds, that the client must wait before retrying the request. You will observe the rate-limiting of your requests in an example application.
Reducing R/U Throughput for a Collection
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmosgroup-lab Resource Group.
-
In the cosmosgroup-lab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node, expand the TransactionCollection node, and then select the Scale & Settings option.
-
In the Settings section, locate the Throughput field and update it’s value to 400.
This is the minimum throughput that you can allocate to an unlimited collection.
-
Click the Save button at the top of the section to persist your new throughput allocation.
Observing Throttling (HTTP 429)
-
Return to the currently open Visual Studio Code editor containing your .NET Core project.
-
In the Visual Studio Code window, right-click the Explorer pane and select the New File menu option.
-
Name the new file Transaction.java . The editor tab will automatically open for the new file.
-
Paste in the following code for the
Transactionclass (be sure that the package declaration matches your classpath):package testpackage; import java.util.ArrayList; import com.github.javafaker.Faker; import com.microsoft.azure.cosmosdb.Document; public class Transaction { Faker faker = new Faker(); ArrayList<Document> documentDefinitions = new ArrayList<>(); public Transaction(int number) throws NumberFormatException { for (int i= 0; i < number;i++){ Document documentDefinition = new Document(); documentDefinition.set("amount", faker.random().nextDouble()); documentDefinition.set("processed", faker.random().nextBoolean()); documentDefinition.set("paidBy", faker.name().firstName() +" "+faker.name().lastName()); documentDefinition.set("costCenter", faker.commerce().department()); documentDefinitions.add(documentDefinition); } } }As a reminder, the java faker library generates test data.
-
Save all of your open editor tabs.
-
Double-click the Program.java link in the Explorer pane to open the file in the editor.
-
Locate the following line of code that identifies the collection that will be used by the application:
private final String collectionId = "PeopleCollection";Replace the line of code with the following line of code:
private final String collectionId = "TransactionCollection";We will use a different collection for the next section of the lab.
-
Locate the createDocument method and replace it with the following:
public void createDocument() throws Exception { ArrayList<Document> documents = new Transaction(5000).documentDefinitions; final ExecutorService executor = Executors.newFixedThreadPool(500); final List<Future<?>> futures = new ArrayList<>(); for (Document document: documents){ // Create a document Future<?> future = executor.submit(() -> { Observable<ResourceResponse<Document>> createDocumentObservable = client .createDocument("dbs/" + databaseName + "/colls/" + collectionId, document, null, false); System.out.println(createDocumentObservable.toBlocking().single().getResource().getId()); }); futures.add(future); } try { for (Future<?> future : futures) { future.get(); // do anything you need, e.g. isDone(), ... } } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } } -
Locate the main method and ensure you are calling the createDocument method:
public static void main(String[] args) { Program p = new Program(); try { p.createDocument(); System.out.println("finished"); } catch (Exception e) { System.err.println(String.format("failed with %s", e)); } System.exit(0); } -
Your Program class should look like this:
public class Program { private final ExecutorService executorService; private final Scheduler scheduler; private final String databaseName = "FinancialDatabase"; private final String collectionId = "PeopleCollection"; private AsyncDocumentClient client; public Program() { executorService = Executors.newFixedThreadPool(100); scheduler = Schedulers.from(executorService); // Sets up the requirements for each test ConnectionPolicy connectionPolicy = new ConnectionPolicy(); connectionPolicy.setConnectionMode(ConnectionMode.Direct); client = new AsyncDocumentClient.Builder() .withServiceEndpoint("uri") .withMasterKeyOrResourceToken("key") .withConnectionPolicy(connectionPolicy).withConsistencyLevel(ConsistencyLevel.Session).build(); DocumentCollection collectionDefinition = new DocumentCollection(); collectionDefinition.setId(UUID.randomUUID().toString()); } /** * Create a document with a programmatically set definition, in an Async manner */ public static void main(String[] args) { Program p = new Program(); try { p.createDocument(); System.out.println("finished"); } catch (Exception e) { System.err.println(String.format("failed with %s", e)); } System.exit(0); } public void createDocument() throws Exception { ArrayList<Document> documents = new Transaction(5000).documentDefinitions; final ExecutorService executor = Executors.newFixedThreadPool(500); final List<Future<?>> futures = new ArrayList<>(); for (Document document: documents){ // Create a document Future<?> future = executor.submit(() -> { Observable<ResourceResponse<Document>> createDocumentObservable = client .createDocument("dbs/" + databaseName + "/colls/" + collectionId, document, null, false); System.out.println(createDocumentObservable.toBlocking().single().getResource().getId()); }); futures.add(future); } try { for (Future<?> future : futures) { future.get(); // do anything you need, e.g. isDone(), ... } } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } } }We are going to try and create 5000 documents with 500 concurrent threads to see if we can hit out throughput limit.
-
Save all of your open editor tabs, and click run.
-
Observe that the application will crash after some time.
This query will most likely hit our throughput limit. You will see multiple error messages indicating that specific requests have failed.
-
Click the 🗙 symbol to close the terminal pane.
Tuning Queries and Reads
You will now tune your requests to Azure Cosmos DB by manipulating properties of the FeedOptions class in the Async Java SDK
Measuring RU Charge
-
Locate the Main method and replace with the following code:
public static void main(String[] args) throws InterruptedException { // as this is a multi collection enable cross partition query FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setPopulateQueryMetrics(true); options.setMaxItemCount(1000); String sql = "SELECT TOP 1000 * FROM c WHERE c.processed = true ORDER BY c.amount DESC"; Program p = new Program(); Observable<FeedResponse<Document>> documentQueryObservable = p.client .queryDocuments("dbs/" + p.databaseName + "/colls/" + p.collectionId, sql, options); // observable to an iterator Iterator<FeedResponse<Document>> it = documentQueryObservable.toBlocking().getIterator(); while (it.hasNext()) { FeedResponse<Document> page = it.next(); ConcurrentMap<String, QueryMetrics> results = page.getQueryMetrics(); System.out.println(results); } }The query will perform a cross-partition ORDER BY and only return the top 1000 out of 50000 documents. the setMaxItemCount ensures that the page size will match the query, and we will only get a single set of query metrics printed to standard out.
-
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
You should see multiple metrics printed out in your console window. Pay close attention to the Total Query Execution Time, Request Charge and Retrieved Document Size metrics.
-
Click the 🗙 symbol to close the terminal pane.
-
Back in the code editor tab, locate the following line of code:
String sql = "SELECT TOP 100 * FROM c WHERE c.processed = true ORDER BY c.amount DESC";Replace that line of code with the following code:
String sql = "SELECT * FROM c WHERE c.processed = true";This new query does not perform a cross-partition ORDER BY.
-
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
You should see a reduction in both the Request Charge and Total Query Execution Time values.
-
Back in the code editor tab, locate the following line of code:
String sql = "SELECT * FROM c WHERE c.processed = true";Replace that line of code with the following code:
String sql = "SELECT * FROM c";This new query does not filter the result set.
-
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
Observe the slight differences in the various metric values.
-
Back in the code editor tab, locate the following line of code:
String sql = "SELECT * FROM c";Replace that line of code with the following code:
String sql = "SELECT c.id FROM c";This new query does not filter the result set.
-
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
Observe the slight differences in the various metric values.
Managing SDK Query Options
-
Locate the using block within the Main method and delete any existing code:
public static void main(String[] args) throws InterruptedException { } -
Add the following additional options for a query:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(100); options.setMaxDegreeOfParallelism(1); options.setMaxBufferedItemCount(0); -
Add the following lines of code to write various values to the console window:
System.out.println(options.getEnableCrossPartitionQuery()); System.out.println(options.getMaxItemCount()); System.out.println(options.getMaxDegreeOfParallelism()); System.out.println(options.getMaxBufferedItemCount()); -
Add the following line of code that will store a SQL query in a string variable:
String sql = "SELECT * FROM c WHERE c.processed = true ORDER BY c.amount DESC";This query will perform a cross-partition ORDER BY on a filtered result set.
-
Add the following line of code to start a high-precision timer:
long startTime = System.nanoTime(); -
Add the following code to create a document query instance and enumerate the resultset:
Program p = new Program(); Observable<FeedResponse<Document>> documentQueryObservable = p.client .queryDocuments("dbs/" + p.databaseName + "/colls/" + p.collectionId, sql, options); // observable to an iterator Iterator<FeedResponse<Document>> it = documentQueryObservable.toBlocking().getIterator(); while (it.hasNext()) { FeedResponse<Document> page = it.next(); List<Document> results = page.getResults(); }Since the results are paged, we will need to call the
hasNextmethod multiple times in a while loop. -
Add the following line of code stop the timer:
long estimatedTime = System.nanoTime() - startTime; -
Add the following line of code to write the timer’s results to the console window:
System.out.println(estimatedTime); -
Save all of your open editor tabs, and click run
-
Observe the output of the console application.
This initial query should take an unexpectedly long amount of time. This will require us to optimize our SDK options.
-
Back in the code editor tab, locate the following lines of code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(100); options.setMaxDegreeOfParallelism(1); options.setMaxBufferedItemCount(0);Replace that line of code with the following code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(100); options.setMaxDegreeOfParallelism(5); options.setMaxBufferedItemCount(0);Setting the
setMaxDegreeOfParallelismproperty to a value of1effectively eliminates parallelism. Here we “bump up” the parallelism to a value of5. -
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
You shouldn’t see a slight difference considering you now have some form of parallelism.
-
Back in the code editor tab, locate the following line of code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(100); options.setMaxDegreeOfParallelism(5); options.setMaxBufferedItemCount(0);Replace that line of code with the following code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(100); options.setMaxDegreeOfParallelism(5); options.setMaxBufferedItemCount(-1);Setting the
setMaxBufferedItemCountproperty to a value of-1effectively tells the SDK to manage this setting. -
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
Again, this should have a slight impact on your performance time.
-
Back in the code editor tab, locate the following line of code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(100); options.setMaxDegreeOfParallelism(5); options.setMaxBufferedItemCount(-1);Replace that line of code with the following code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(100); options.setMaxDegreeOfParallelism(-1); options.setMaxBufferedItemCount(-1);Parallel query works by querying multiple partitions in parallel. However, data from an individual partitioned collect is fetched serially with respect to the query Setting the
setMaxDegreeOfParallelismproperty to a value of-1effectively tells the SDK to manage this setting. Setting the setMaxDegreeOfParallelism to the number of partitions has the maximum chance of achieving the most performant query, provided all other system conditions remain the same. -
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
Again, this should have a slight impact on your performance time.
-
Back in the code editor tab, locate the following line of code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(100); options.setMaxDegreeOfParallelism(-1); options.setMaxBufferedItemCount(-1);Replace that line of code with the following code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(500); options.setMaxDegreeOfParallelism(-1); options.setMaxBufferedItemCount(-1);We are increasing the amount of items returned per “page” in an attempt to improve the performance of the query.
-
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
You will notice that the query performance improved dramatically. This may be an indicator that our query was bottlenecked by the client computer.
-
Back in the code editor tab, locate the following line of code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(500); options.setMaxDegreeOfParallelism(-1); options.setMaxBufferedItemCount(-1);Replace that line of code with the following code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(1000); options.setMaxDegreeOfParallelism(-1); options.setMaxBufferedItemCount(-1);For large queries, it is recommended that you increase the page size up to a value of 1000.
-
Save all of your open editor tabs, anc click run.
-
Observe the output of the console application.
By increasing the page size, you have sped up the query even more.
-
Back in the code editor tab, locate the following line of code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(1000); options.setMaxDegreeOfParallelism(-1); options.setMaxBufferedItemCount(-1);Replace that line of code with the following code:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); options.setMaxItemCount(1000); options.setMaxDegreeOfParallelism(-1); options.setMaxBufferedItemCount(50000);Parallel query is designed to pre-fetch results while the current batch of results is being processed by the client. The pre-fetching helps in overall latency improvement of a query. setMaxBufferedItemCount is the parameter to limit the number of pre-fetched results. Setting MaxBufferedItemCount to the expected number of results returned (or a higher number) allows the query to receive maximum benefit from pre-fetching.
-
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
This change should have decreased your query time by a small amount.
-
Click the 🗙 symbol to close the terminal pane.
Reading and Querying Documents
-
Locate the Main method and delete any existing code:
public static void main(String[] args) throws InterruptedException { } -
Add the following line of code that will store a SQL query in a string variable:
String sql = "SELECT TOP 1 * FROM c";This query will find a single document matching the specified unique id
-
Add the following lines of code to create a document query instance:
FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); Program p = new Program(); Observable<FeedResponse<Document>> documentQueryObservable = p.client .queryDocuments("dbs/" + p.databaseName + "/colls/" + p.collectionId, sql, options); -
Add the following line of code to print out the value of the RequestCharge property of the ResourceResponse<> instance:
System.out.println(documentQueryObservable.toBlocking().single().getRequestCharge()); -
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
You should see the amount of RUs used to query for the document in your collection.
-
Click the 🗙 symbol to close the terminal pane.
Viewing the ETag Property of a Requested Resource
The SQL API supports optimistic concurrency control (OCC) through HTTP entity tags, or ETags. Every SQL API resource has an ETag, and the ETag is set on the server every time a document is updated. In this exercise, we will view the ETag property of a resource that is requested using the SDK.
Observe the ETag Property.
-
Locate the Main method and delete any existing code:
public static void main(String[] args) throws InterruptedException { } -
Within the Main method, locate the following line of code:
System.out.println(documentQueryObservable.toBlocking().single().getRequestCharge());Replace that line of code with the following code:
Iterator<FeedResponse<Document>> it = documentQueryObservable.toBlocking().getIterator(); while (it.hasNext()) { FeedResponse<Document> page = it.next(); List<Document> results = page.getResults(); for (Document doc : results) { System.out.println(doc.getETag()); } }The ETag header and the current value are included in all response messages.
-
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
You should see an ETag for the document.
-
Click run again.
-
Observe the output of the console application.
The ETag should remain unchanged since the document has not been changed.
-
Click the 🗙 symbol to close the terminal pane.
-
Locate the Main method:
public static void main(String[] args) throws InterruptedException { String sql = "SELECT TOP 1 * FROM c"; FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); Program p = new Program(); Observable<FeedResponse<Document>> documentQueryObservable = p.client .queryDocuments("dbs/" + p.databaseName + "/colls/" + p.collectionId, sql, options); Iterator<FeedResponse<Document>> it = documentQueryObservable.toBlocking().getIterator(); while (it.hasNext()) { FeedResponse<Document> page = it.next(); List<Document> results = page.getResults(); for (Document doc : results) { System.out.println(doc.getETag()); } } } -
Replace it with the following code:
public static void main(String[] args) throws InterruptedException { String sql = "SELECT TOP 1 * FROM c"; FeedOptions options = new FeedOptions(); options.setEnableCrossPartitionQuery(true); Program p = new Program(); Observable<FeedResponse<Document>> document = p.client .queryDocuments("dbs/" + p.databaseName + "/colls/" + p.collectionId, sql, options); Iterator<FeedResponse<Document>> it = document.toBlocking().getIterator(); RequestOptions roptions; while (it.hasNext()) { FeedResponse<Document> page = it.next(); List<Document> results = page.getResults(); for (Document doc : results) { System.out.println(doc.getETag()); AccessCondition cond = new AccessCondition(); cond.setCondition(doc.getETag()); cond.setType(AccessConditionType.IfMatch); doc.set("FirstName", "Demo"); roptions = new RequestOptions(); Observable<ResourceResponse<Document>> response = p.client.replaceDocument(doc, roptions); System.out.println(response.toBlocking().single().getResource().getETag()); } } } -
Save all of your open editor tabs, and click run.
-
Observe the output of the console application.
You should see that the value of the ETag property has changed. The AccessCondition class helped us implement optimistic concurrency by specifying that we wanted the SDK to use the If-Match header to allow the server to decide whether a resource should be updated. The If-Match value is the ETag value to be checked against. If the ETag value matches the server ETag value, the resource is updated. If the ETag is no longer current, the server rejects the operation with an “HTTP 412 Precondition failure” response code. The client then re-fetches the resource to acquire the current ETag value for the resource.
-
Click the 🗙 symbol to close the terminal pane.
-
Close all open editor tabs.
-
Close the Visual Studio Code application.
-
Close your browser application.